Neural style transfer is a technique that allows us to merge two images, taking style from one image and content from another image, resulting in a new and unique image. For example, one could transform their painting into an artwork that resembles the work of artists like Picasso or Van Gogh.
Here is how this technique works, at that start you have three images, a pixelated image, the content image, and a style image, the Machine Learning model transforms the pixelated image into a new image that maintains recognizable features from the content and style image.
Neural Style Transfer (NST) has several use cases, such as photographers enhancing their images by applying artistic styles, marketers creating engaging content, or an artist creating a unique and new art form or prototyping their artwork.
In this blog, we will explore NST, and how it works, and then look at some possible scenarios where one could make use of NST.

Neural Style Transfer Explained
Neural Style Transfer follows a simple process that involves:
- Three images, the image from which the style is copied, the content image, and a starting image that is just random noise.
- Two loss values are calculated, one for style Loss and another for content loss.
- The NST iteratively tries to reduce the loss, at each step by comparing how close the pixelated image is to the content and style image, and at the end of the process after several iterations, the random noise has been turned into the final image.
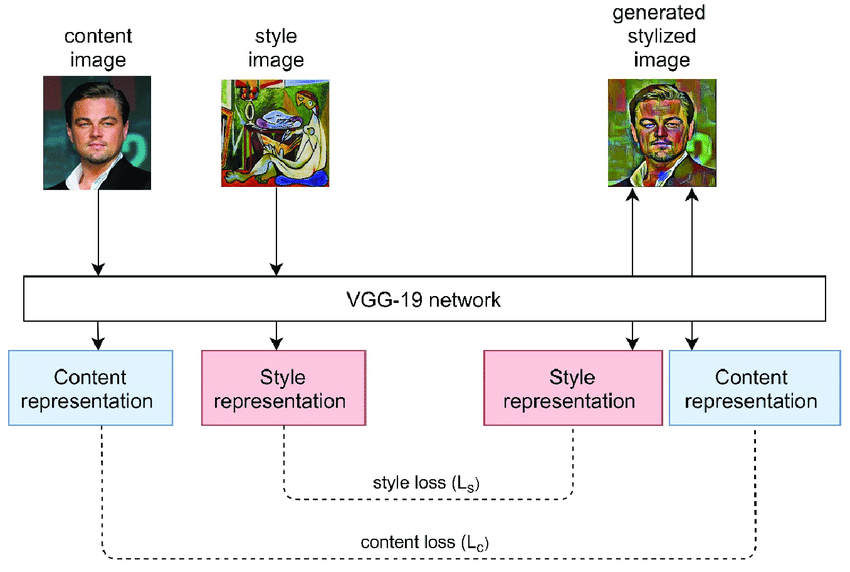
Difference between Style and Content Image
We have been talking about Content and Style Images, let’s look at how they differ from each other:
- Content Image: From the content image, the model captures the high-level structure and spatial features of the image. This involves recognizing objects, shapes, and their arrangements within the image. For example, in a photograph of a cityscape, the content representation is the arrangement of buildings, streets, and other structural elements.
- Style Image: From the Style image, the model learns the artistic elements of an image, such as textures, colors, and patterns. This would include color palettes, brush strokes, and texture of the image.

By optimizing the loss, NST combines the two distinct representations in the Style and Content image and combines them into a single image given as input.
Background and History of Neural Style Transfer
NST is an example of an image styling problem that has been in development for decades, with image analogies and texture synthesis algorithms paving foundational work for NST.
- Image Analogies: This approach learns the “transformation” between a photo and the artwork it is trying to replicate. The algorithm then analyzes the differences between both the photos, these learned differences are then used to transform a new photo into the desired artistic style.
- Image Quilting: This method focuses on replicating the texture of a style image. It first breaks down the style image into small patches and then replaces these patches in the content image.

The field of Neural style transfer took a completely new turn with Deep Learning. Previous methods used image processing techniques that manipulated the image at the pixel level, attempting to merge the texture of one image into another.
With deep learning, the results were impressively good. Here is the journey of NST.
Gatys et al. (2015)
The research paper by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge, titled “A Neural Algorithm of Artistic Style,” made an important mark in the timeline of NST.
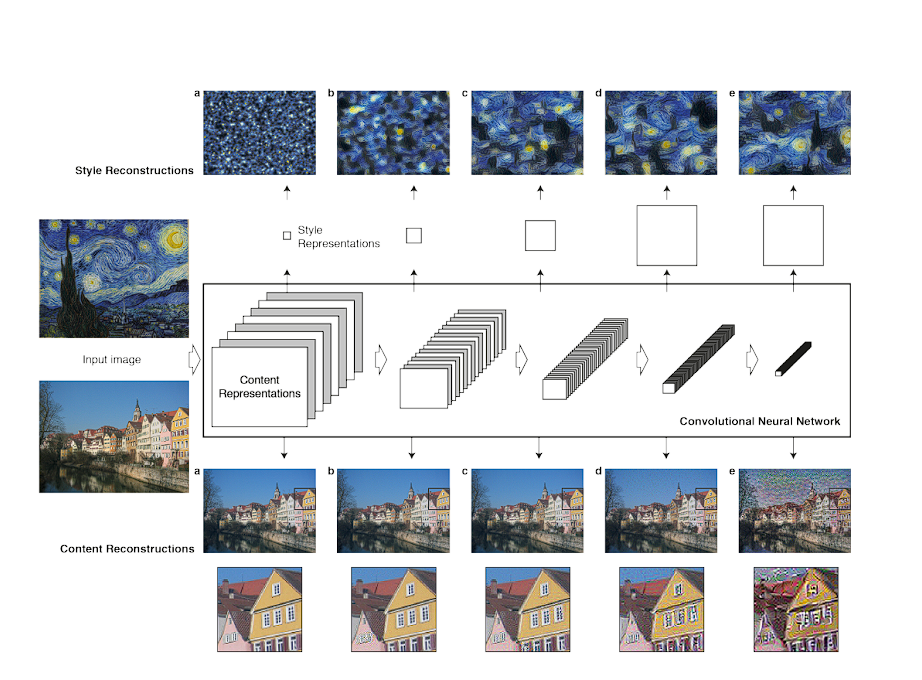
The researchers repurposed the VGG-19 architecture that was pre-trained for object detection to separate and recombine the content and style of images.
- The model analyzes the content image through the pre-trained VGG-19 model, capturing the objects and structures. It then analyses the style image using an important concept, the Gram Matrix.
- The generated image is iteratively refined by minimizing a combination of content loss and style loss. Another key concept in this model was the use of a Gram matrix.
What is Gram Matrix?
A Gram matrix captures the style information of an image in numerical form.
An image can be represented by the relationships between the activations of features detected by a convolutional neural network (CNN). The Gram matrix focuses on these relationships, capturing how often certain features appear together in the image. This is done by minimizing the mean-squared error distance between the entries of the Gram matrix from the original image and the Gram matrix of the image to be generated.
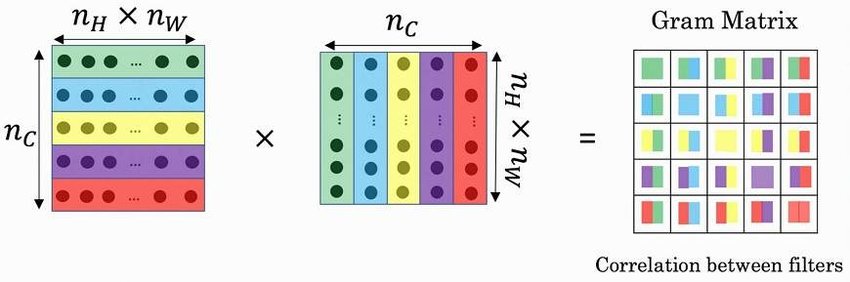
A high value in the Gram matrix indicates that certain features (represented by the feature maps) frequently co-occur in the image. This tells about the image’s style. For example, a high value between a “horizontal edge” map and a “vertical edge” map would indicate that a certain geometric pattern exists in the image.
The style loss is calculated using the gram matrix, and content loss is calculated by analyzing the higher layers in the model, chosen consciously because the higher level captures the semantic details of the image such as shape and layout.
This model uses the technique we discussed above where it tries to reduce the Style and Content loss.
Johnson et al. Fast Style Transfer (2016)
While the previous model produced decent results, it was computationally expensive and slow.
In 2016, Justin Johnson, Alexandre Alahi, and Li Fei-Fei addressed computation limitations by publishing their research paper titled “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.”
In this paper, they introduced a network that could perform style transfer in real-time using perceptual loss, in which instead of using direct pixel values to calculate Gram Matrix, perceptual loss uses the CNN model to capture the style and content loss.
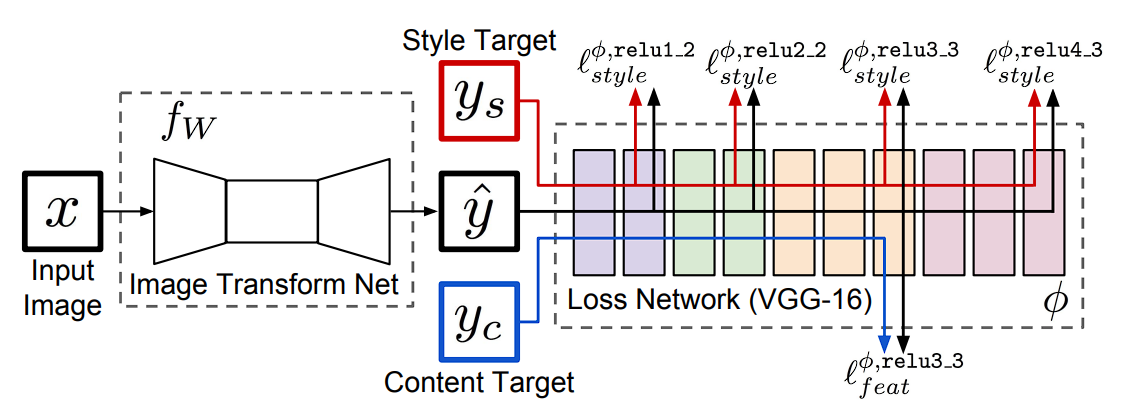
The two defined perceptual loss functions make use of a loss network, therefore it is safe to say that these perceptual loss functions are themselves Convolution Neural Networks.
What is Perceptual Loss?
Perceptual loss has two components:
- Feature Reconstruction Loss: This loss encourages the model to have output images that have a similar feature representation to the target image. The feature reconstruction loss is the squared, normalized Euclidean distance between the feature representations of the output image and target image. Reconstructing from higher layers preserves image content and overall spatial structure but not color, texture, and exact shape. Using a feature reconstruction loss encourages the output image y to be perceptually similar to the target image y without forcing them to match exactly.
- Style Reconstruction Loss: The Style Reconstruction Loss aims to penalize differences in style, such as colors, textures, and common patterns, between the output image and the target image. The style reconstruction loss is defined using the Gram matrix of the activations.
During style transfer, the perceptual loss method using the VGG-19 model extracts features from the content (C) and style (S) images.
Once the features are extracted from each image perceptual loss calculates the difference between these features. This difference represents how well the generated image has captured the features of both the content image (C) and the style image (S).
This innovation allowed for fast and efficient style transfer, making it practical for real-world applications.

Huang and Belongie (2017): Arbitrary Style Transfer
Xun Huang and Serge Belongie further advanced the field with their 2017 paper named, “Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization (AdaIN).”
The model introduced in Fast Style Transfer did speed up the process. However, the model was limited to a certain set of styles only.
The model based on Arbitrary style transfer allows for random style transfer using AdaIN layers. This gave the liberty to the user to control content style, color, and spatial controls.
What is AdaIN?
AdaIN, or Adaptive Instance Normalization aligns the statistics (mean and variance) of content features with those of style features. This injected the user-defined style information into the generated image.
This gave the following benefits:
- Arbitrary Styles: The ability to transfer the characteristics of any style image onto a content image, regardless of the content or style’s specific characteristics.
- Fine Control: By adjusting the parameters of AdaIN (such as the style weight or the degree of normalization), the user can control the intensity and fidelity of the style transfer.
SPADE (Spatially Adaptive Normalization) 2019

Park et al. introduced SPADE, which has played a great role in the field of conditional image synthesis (conditional image synthesis refers to the task of generating photorealistic images conditioning on certain input data). Here the user gives a semantic image, and the model generates a real image out of it.
This model uses specially adaptive normalization to achieve the results. Previous methods directly fed the semantic layout as input to the deep neural network, which then the model processed through stacks of convolution, normalization, and nonlinearity layers. However, the normalization layers in this washed away the input image, resulting in lost semantic information. This allowed for user control over the semantics and style of the image.
GANs based Models
GANs were first introduced in 2014 and have been modified for use in various applications, style transfer being one of them. Here are some of the popular GAN models that are used:
CycleGAN

- Authors: Zhu et al. (2017)
- CycleGAN uses unpaired image datasets to learn mappings between domains to achieve image-to-image translation. It can learn the transformation by looking at lots of images of horses and lots of images of zebras, and then figure out how to turn one into the other.
StarGAN

- Authors: Choi et al. (2018)
- StarGAN extends GANs to multi-domain image translation. Before this, GANs were able to translate between two specific domains only, i.e., photo to painting. However, starGAN can handle multiple domains, which means it can change hair color, add glasses, change facial expression, etc. Without needing a separate model for each image translation task.
DualGAN:
- Authors: Yi et al. (2017)
- DualGAN introduces dual learning where two GANs are trained simultaneously for forward and backward transformations between two domains. DualGAN has been applied to tasks like style transfer between different artistic domains.
Applications of Neural Style Transfer
Neural Style Transfer has been used in diverse applications that scale across various fields. Here are some examples:
Artistic Creation
NST has revolutionized the world of art creation by enabling artists to experiment by blending content from one image with the style of another. This way artists can create unique and visually stunning pieces.
Digital artists can use NST to experiment with different styles quickly, allowing them to prototype and explore new forms of artistic creation.

This has introduced a new way of creating art, a hybrid form. For example, artists can combine classical painting styles with modern photography, producing a new hybrid art form.
Moreover, these Deep Learning models are visible in various applications on mobile and web platforms:
- Applications like Prisma and DeepArt are powered by NST, enabling them to apply artistic filters to user photos, making it easy for common people to explore art.
- Websites and software like Deep Dream Generator and Adobe Photoshop’s Neural Filters offer NST capabilities to consumers and digital artists.
Image Enhancement
NST is also used widely to enhance and stylize images, giving new life to older photos that might be blurred or lose their colors. Giving new opportunities for people to restore their images and photographers.

For example, Photographers can apply artistic styles to their images, and transform their images to a particular style quickly without the need of manually tuning their images.
Video Enhancement
Videos are picture frames stacked together, therefore NST can be applied to videos as well by applying style to individual frames. This has immense potential in the world of entertainment and movie creation.
For example, directors and animators can use NST to apply unique visual styles to movies and animations, without the need for heavily investing in dedicated professionals, as the final video can be edited and enhanced to give a cinematic or any kind of style they like. This is especially valuable for individual movie creators.
What’s Next with NST
In this blog, we looked at how NST works by taking a style image and content image and combining them, turning a pixelated image into an image that has mixed up the style representation and content representation. This is performed by iteratively reducing the style loss and content representation loss.
We then looked at how NST has progressed over time, from its inception in 2015 where it used Gram Matrices to perceptual loss and GANs.
Concluding this blog, we can say NST has revolutionized art, photography, and media, enabling the creation of personalized art, and creative marketing materials, by giving individuals the ability to create art forms that would not been possible before.
Enterprise AI
Viso Suite infrastructure makes it possible for enterprises to integrate state-of-the-art computer vision systems into their everyday workflows. Viso Suite is flexible and future-proof, meaning that as projects evolve and scale, the technology continues to evolve as well. To learn more about solving business challenges with computer vision, book a demo with our team of experts.