
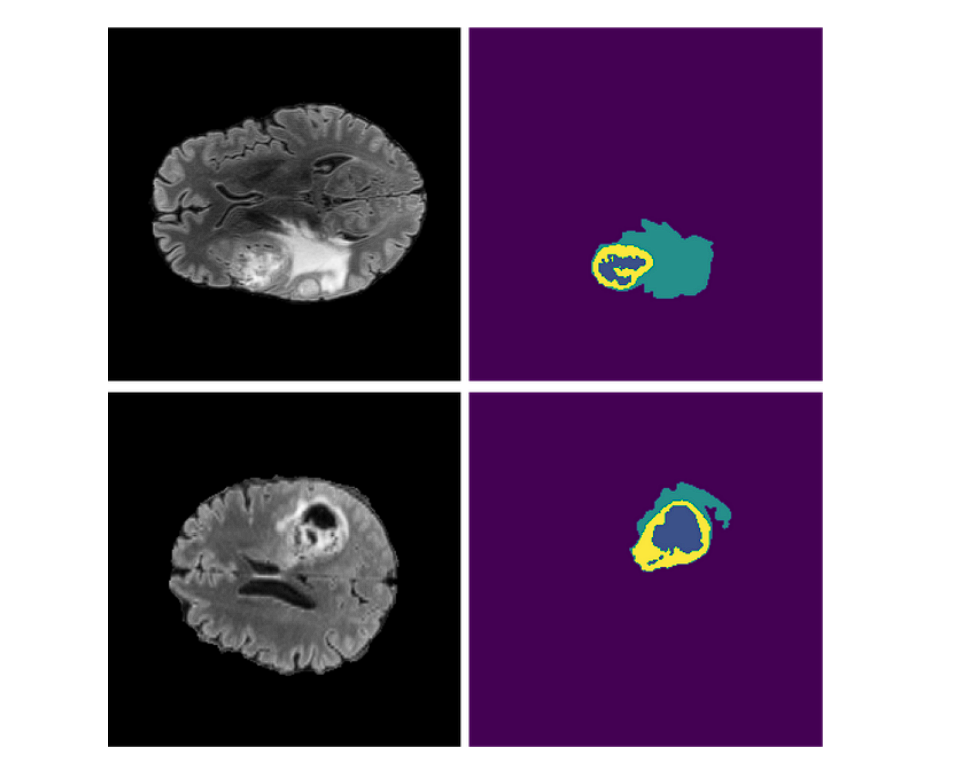
In computer vision, image segmentation breaks down an image into distinct segments or regions for easier analysis. This technique helps precisely identify objects, boundaries, and contours, making it crucial for medical imaging, autonomous vehicles, and satellite imagery analysis.
Healthcare leverages image segmentation extensively for precisely segmenting medical scans which aids in diagnosing and monitoring diseases.
U-Net, a deep learning model specifically designed for biomedical image segmentation, exemplifies this. Introduced in 2015 by Olaf Ronneberger’s team, U-Net aimed to create a high-performing network that could work with limited training data, addressing the challenge of scarce annotated images in the medical field.
Challenges in Image Segmentation
Before the advanced deep learning models like U-Net and Mask R-CNN, image segmentation faced several significant challenges.
- Precision and Accuracy: Traditional methods struggled with accurately segmenting images, especially those with varying textures, complex structures, or noise. Researchers used techniques such as thresholding, region-based segmentation, and edge detection; however, these methods did not deliver the necessary detail and accuracy for complex applications like medical imaging.
- Dependence on Handcrafted Features: Earlier approaches relied heavily on manual feature extraction methods which were time-consuming and less robust.
- Scalability and Efficiency: Due to handcrafted feature extractors, it was nearly impossible to scale the model, as doing so would require one to handcraft all the features required for the image variations.
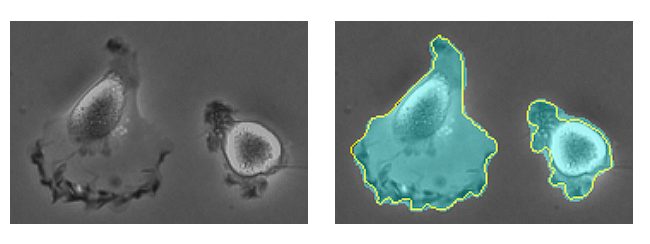
The process of image segmentation
Deep Learning models have solved the limitations discussed above. Several deep-learning models are used for image segmentation, such as U-Net, Fully Convolutional Networks (FCN), and Mask R-CNN. However, all of these models roughly follow the following procedure for image segmentation.
- Data Preparation: To train a deep learning model for image segmentation, you must prepare a substantial amount of annotated data. This involves labeling images at the pixel level and assigning a class label to each pixel.
- Pre-processing: This step includes resizing images, augmenting the dataset with techniques like flipping, rotating, and altering brightness to improve the model’s robustness, and normalizing the images to enhance learning efficiency.
- Model Training: You train the model on the annotated dataset, enabling it to learn how to classify each pixel of the input image into a relevant class.
- Post-processing: After the model predicts the pixel classes, you apply post-processing steps such as removing small islands of misclassified pixels or using Conditional Random Fields (CRFs) to refine the results.
- Visualization: To visualize the segmentation in the post-processing step, you map each unique class value to a specific color. This mapping is arbitrary and chosen to maximize the contrast between different classes for easier visual distinction.
Key Innovations in U-Net
As mentioned earlier, researchers initially created U-Net for medical image segmentation, but it soon gained popularity across various other segmentation applications. The widespread adoption is due to the innovative techniques and methods used in its design.
- Symmetric Expanding Path: Unlike previous models such as FCN, which had only contracting paths, U-Net introduced a U-shaped architecture that consists of an encoding path to capture context and a decoding path that enables precise localization.
- Skip Connections: These connect the contracting path with the expansive path, retrieving spatial information lost during down-sampling.
- Data Augmentation: To tackle the issue of limited training data, U-Net employed extensive data augmentation techniques which allowed the model to learn more robust features without needing a vast number of annotated samples.
Advantages of U-Net:
- High Accuracy with Limited Data: U-Net achieves excellent performance even with small training datasets due to its architecture and data augmentation strategies.
- Precise Localization: The combination of low-level and high-level features through skip connections allows for precise localization of object boundaries.
- Fast and Efficient: U-Net’s fully convolutional architecture enables efficient processing of large images with fast segmentation speeds.
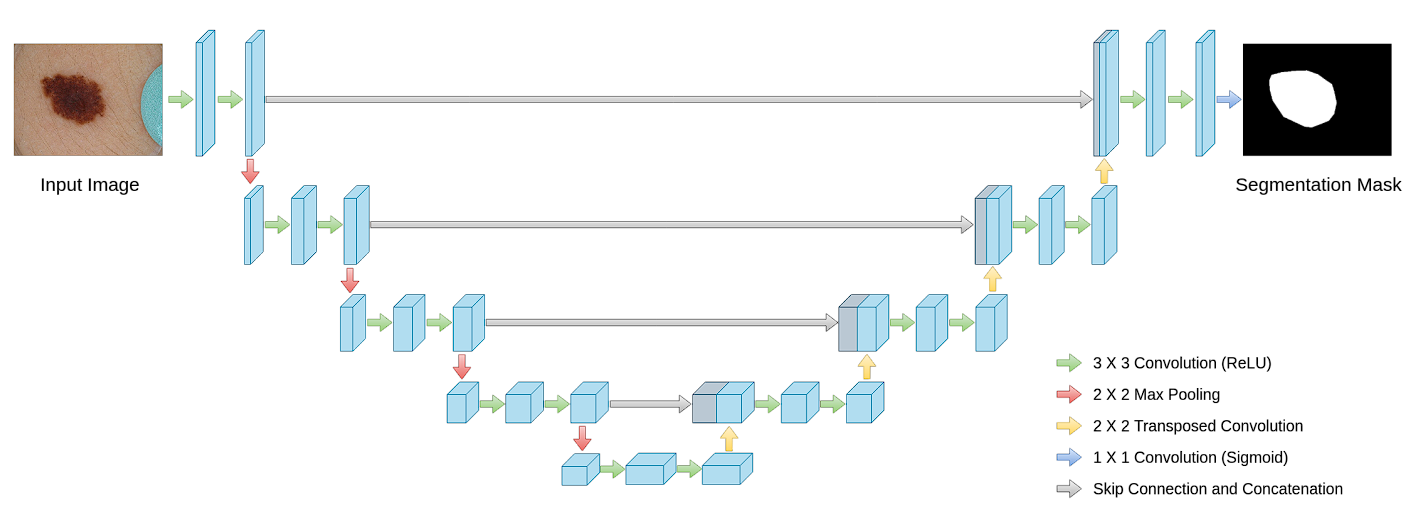
Architecture of U-Net
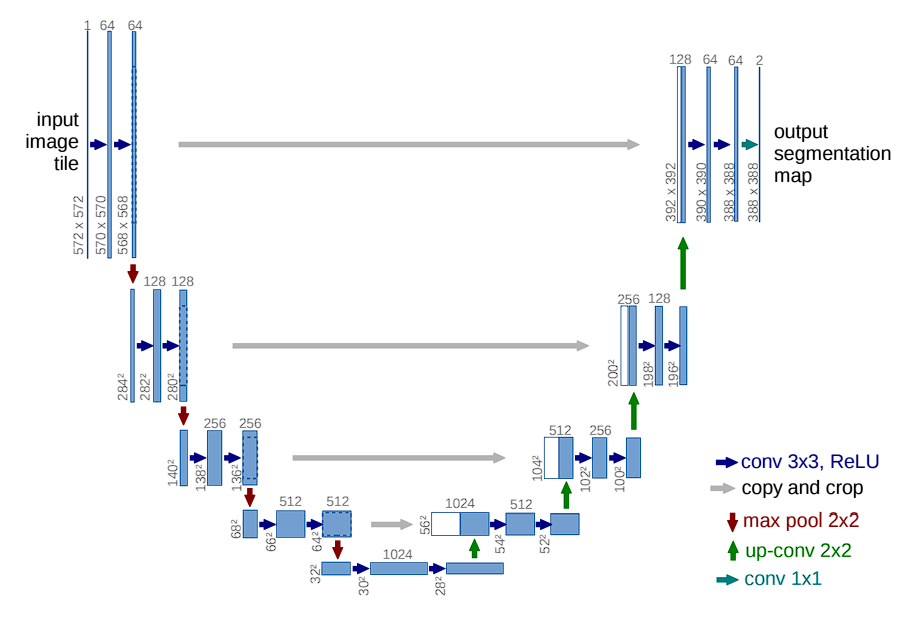
The model features a distinctive U-shaped structure, comprising two main parts: the contracting path (encoder) and the expanding path (decoder). The encoding path captures context, and the decoding path enables precise localization.
Contracting Path (Encoder)
Here are the different layers and components in U-Net:
- Convolutional Layers: Convolution Layers are the primary components of the contracting path. In the originally proposed model, each block consists of two consecutive 3×3 convolutional layers followed by a Rectified Linear Unit (ReLU) activation function. By stacking multiple convolutional layers, U-Net learns increasingly complex features.
- Activation Functions: After each convolution operation, a ReLU activation function is applied. The role of ReLU here is crucial as it introduces non-linearities into the system, which allows for learning more complex patterns in data that are not possible with just linear transformations.
- Max Pooling: Following the convolutional layers, a 2×2 max pooling operation with stride 2 is used. This step reduces the spatial dimensions by half. However, it captures abstract information (that makes the model invariant to small shifts and distortions).
- Feature Doubling: After each max pooling step, the subsequent convolutional layer doubles the number of filters used. For example, if a layer starts with 64 feature channels, it will have 128 channels after the next pooling and convolution operations. By doubling the number of feature channels, the network can maintain or even increase its capacity to represent information despite the reduction in spatial resolution. This is crucial because the risk of losing important details increases as the image size reduces.
Expansive Path (Decoder)
Aims to recover spatial information and generate the segmentation map using up-convolution (or transposed convolution).
Each block includes:
- Up-sampling of the feature map to increase image size.
- A 2×2 convolution to halve the number of feature channels.
- Two 3×3 convolutions followed by ReLU activation.
U-Net also uses skip connections.
What are skip connections?
Skip connections significantly contribute to U-Net’s effectiveness. By merging feature maps from the contracting path directly with the expanding path, U-Net combines low-level detail information with high-level contextual information across the network.
Here is why it is important.
- Recover Spatial Hierarchies: These connections allow U-Net to concatenate high-resolution features from the contracting path with up-sampled outputs from the expanding path. This helps recover spatial hierarchies lost during pooling operations in the contracting phase.
Output
At the final layer of the Convolutional Neural Network, a 1×1 convolution maps the feature vector (typically with 64 components at the last stage of the expansive path) to the desired number of classes for segmentation.
Overlap-Tile Strategy
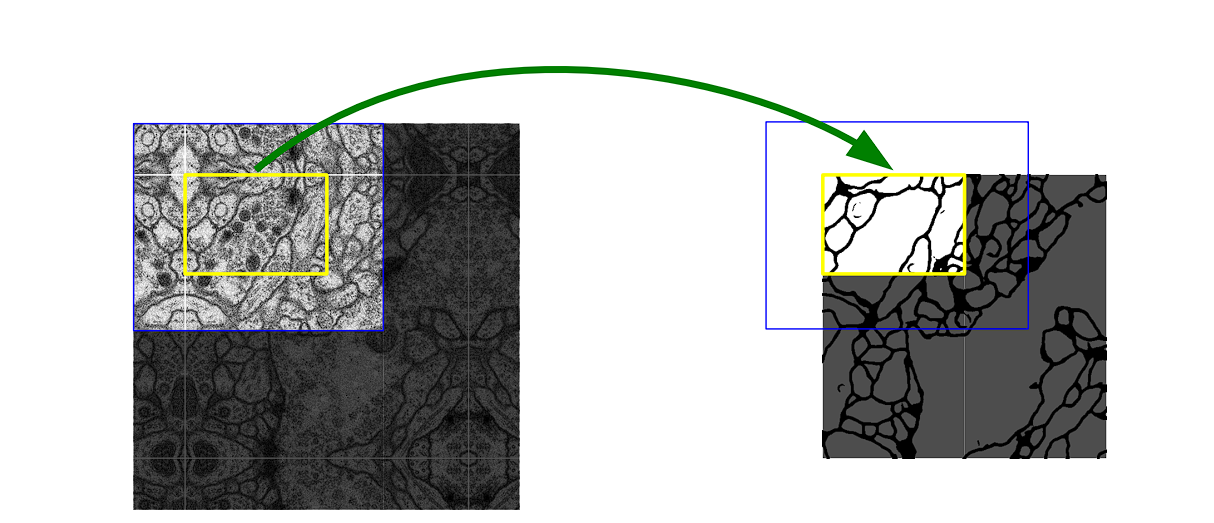
To effectively predict segments in border regions of images for each pixel’s classification, U-Net employs an overlap-tile strategy. This allows U-Net to handle large images by segmenting them into small manageable sections of an image and then stitching them together.
- Tile Processing: Instead of processing whole images (which is computationally extensive), the network divides images into overlapping tiles that can fit into it.
- Overlap Handling: The overlaps between tiles help continuity and prevent inaccuracies at tile boundaries.
Data Augmentation
In scenarios like medical imaging where annotated samples are limited, data augmentation assumes a critical role.
Data augmentation is the process of artificially increasing the size of a training set using transformations such as rotations, elastic deformations, and scaling. This helps improve model generalization and robustness by introducing it to different types of images. Here are some of the variations applied:
- Biased crop: Randomly crops patches with a bias towards including foreground.
- Zoom: Randomly zooms in on the image.
- Flipping of Image
- Gaussian Noise: Adds random noise to the input.
- Gaussian Blur
- Brightness and Contrast: Randomly adjusts brightness and contrast.
Performance Benchmarks
The published paper of U-Net shows exceptional performance in medical image analysis, with U-Net outperforming all the previous methods on the ISBI EM segmentation challenge, achieving state-of-the-art results.
The model was applied to two different datasets of light microscopic images and the following results were obtained:
- PhC-U373 Dataset: Achieving an average Intersection Over Union (IOU) of 92%, the highest among competitors.
- DIC-HeLa Dataset: Achieving a 77.5% IOU, again outperforming other models significantly.
U-Net Variants
Since the introduction of U-Net, various adaptations have been developed to tackle specific challenges or enhance performance. Some notable variants include:
3D U-Net
Adapted from the original U-Net for volumetric segmentation, the 3D U-Net extends the architecture to three dimensions by utilizing 3-D convolutions which allows for analyzing 3D medical images like CT or MRI scans for organ segmentation and tumor identification.
Residual U-Net:
This variant adds residual connections within the convolutional blocks of the U-Net architecture. The residual connections can help mitigate the vanishing gradient problem and enable the training of deeper networks.
Attention U-Net
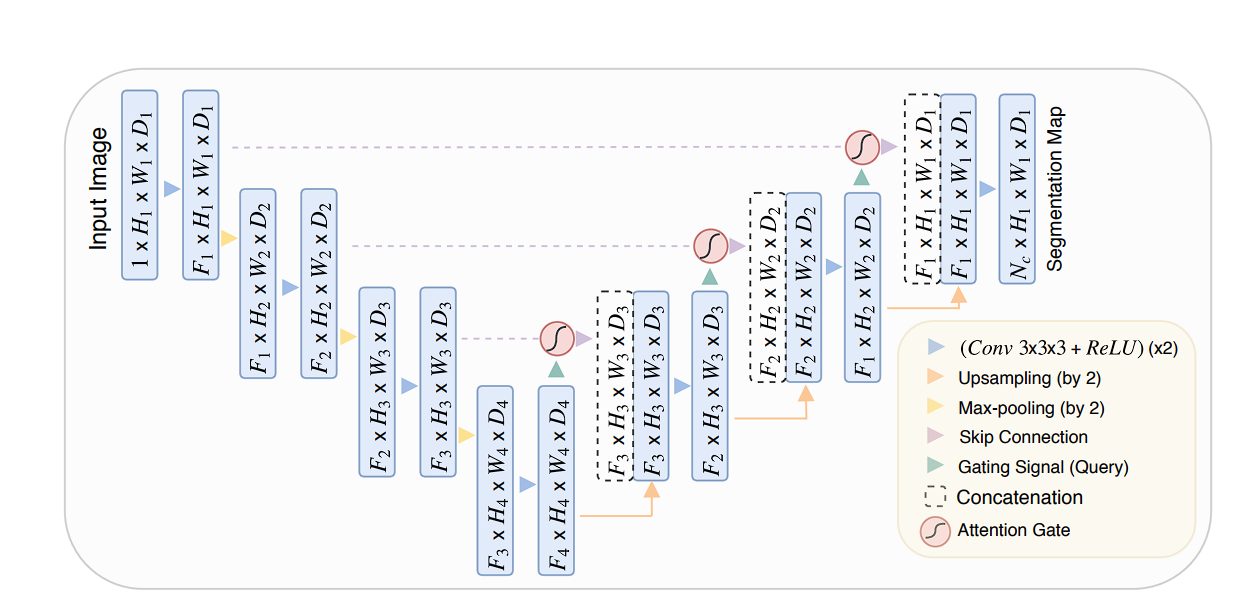
This variant integrates attention mechanisms into the standard U-Net architecture. The Attention gates learn to focus on relevant regions of the encoder feature maps by assigning weights based on the context. They improve the model’s performance leading to more precise segmentation boundaries.
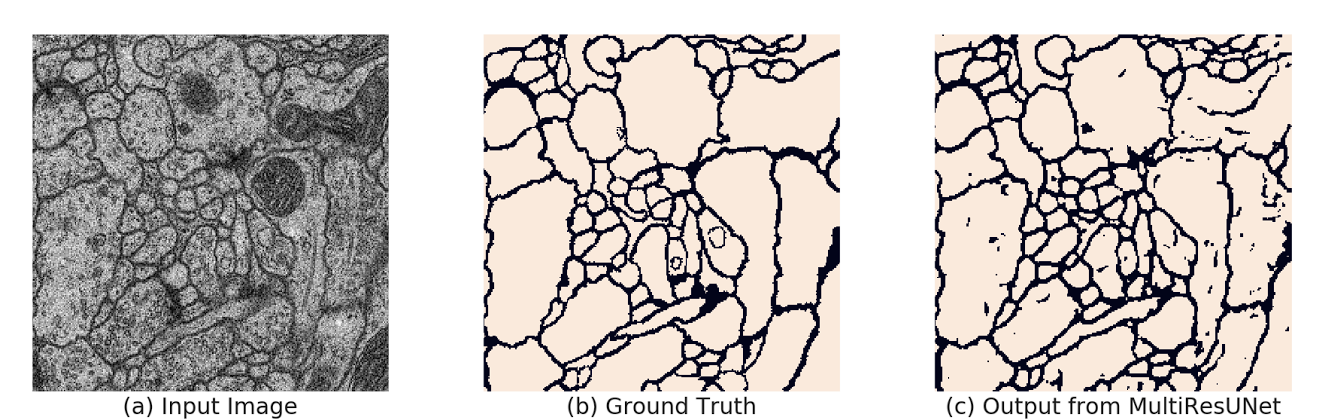
MultiResUNet
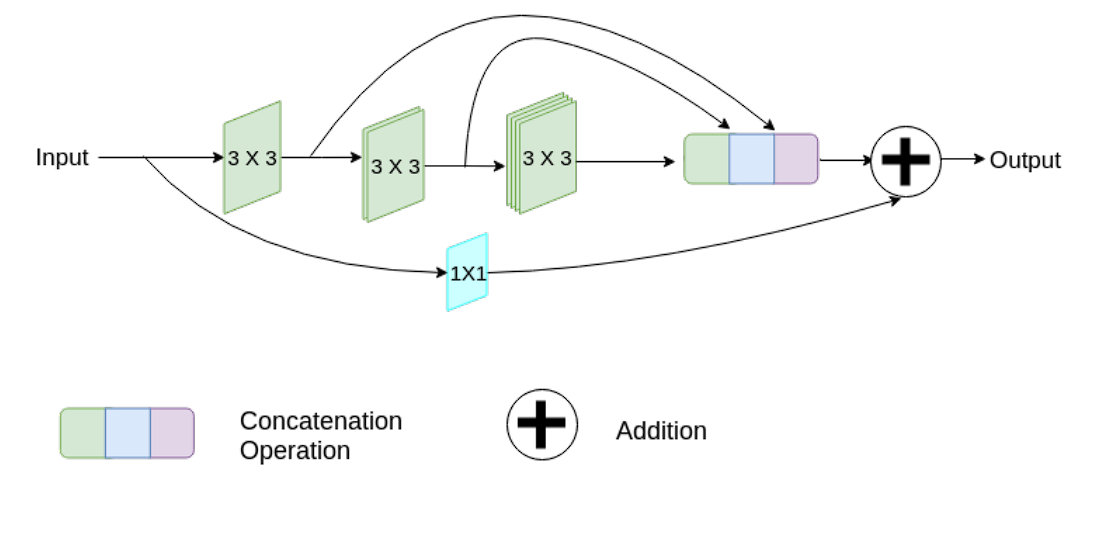
MultiResUNet introduces the concept of Multi-Resolution blocks at each stage of the network. These blocks consist ‘of several parallel convolutional pathways with varying kernel sizes that capture features at different resolutions.
Moreover, it also incorporates residual connections, which help in combating the vanishing gradient problem.
UNETR
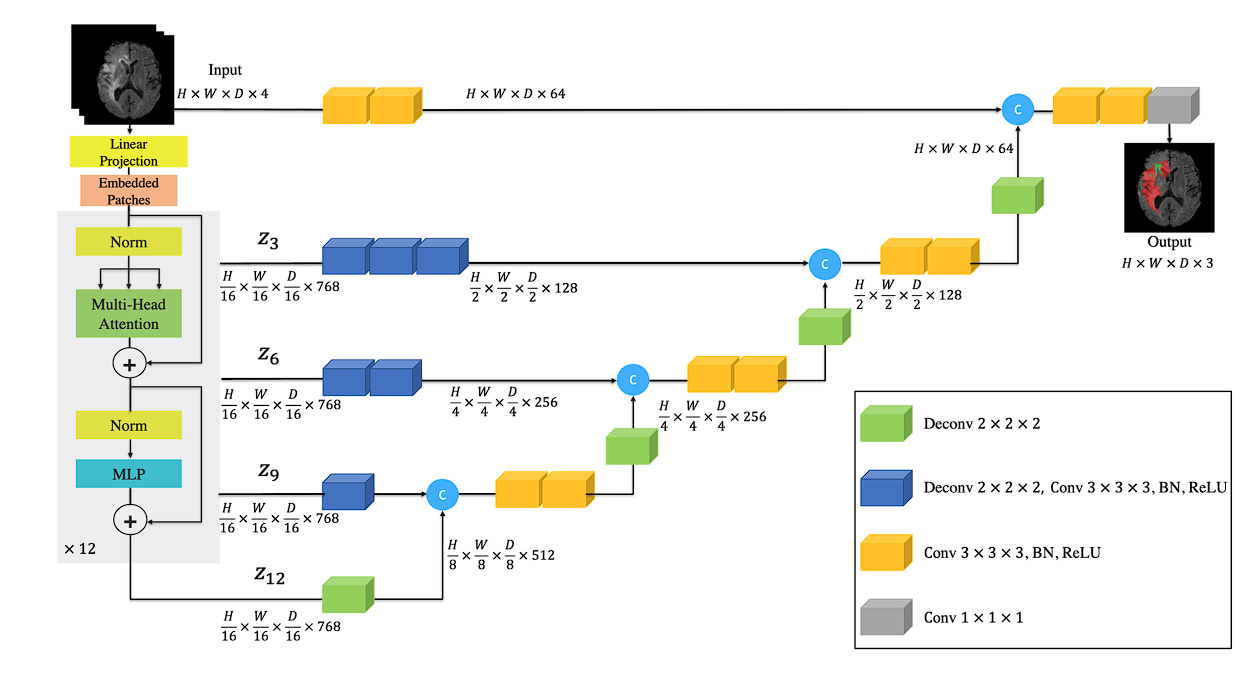
The UNETR model replaces the convolutional encoder of U-Net with a transformer-based encoder that leverages self-attention mechanisms.
The self-attention mechanism allows the model to capture long-range dependencies and global context within the input data, potentially improving segmentation accuracy.
Applications of U-Net
U-Net’s design, characterized by its efficiency and precision, has made it profoundly impactful across various domains beyond its initial biomedical applications. Here are some key areas where U-Net has been extensively applied:
Medical Image Segmentation
U-Net is especially popular in the field of medical image segmentation due to its ability to provide detailed and accurate segmentations of complex anatomical structures.
- Organs: U-Net has been utilized to segment various organs in different types of medical scans (CT, MRI, Ultrasound). For instance, it helps in delineating the boundaries of the liver, heart, lungs, and pancreas which is crucial for surgical planning and diagnosis.

- Tumors: U-Net is used for precise tumor segmentation on radiological images, to accurately distinguish tumors from healthy tissues.
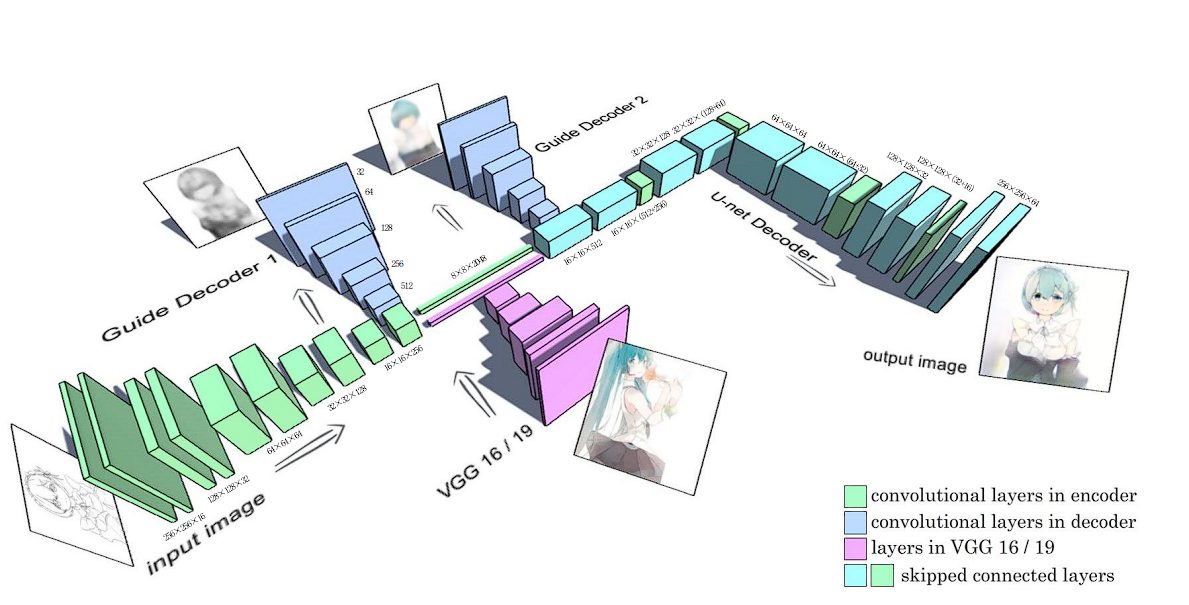
Style Transfer
U-Net combined with GANs has been used for style transfer for Anime sketches. The generator in the GAN is based on a U-net with skip-connection layers. Read here.
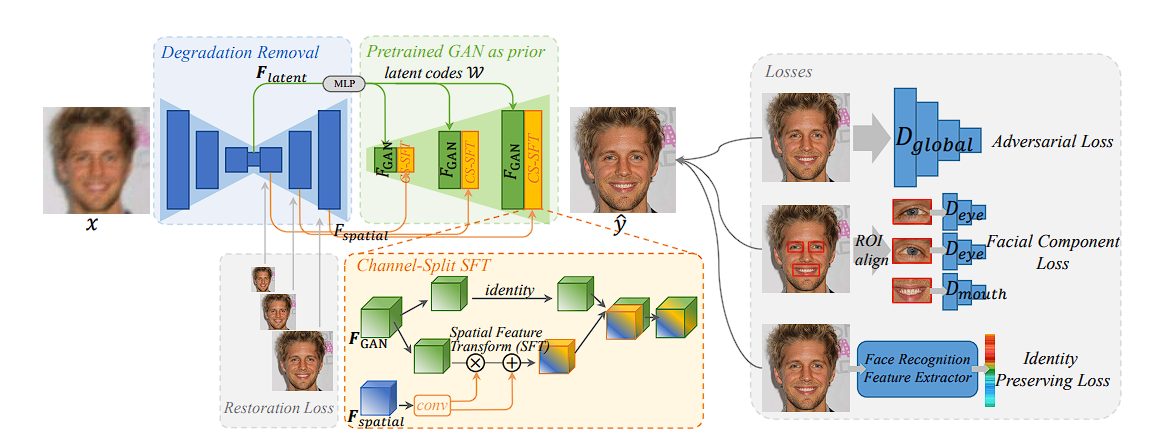
Face Restoration
Implementers have utilized pre-trained face Generative Adversarial Network (GAN) models, such as StyleGAN, for blind face restoration. In this implementation, UNet removes degradations such as low-resolution, blur, noise, and JPEG artifacts. Read here.
Conclusion
In this blog, we looked at the U-shaped architecture of U-Net, which performs exceptionally well in fields like medical imaging where training data is limited. Moreover, the encoder and decoder part of the model allows for abstract representation and localization of objects, which plays a key role in various applications such as tumor detection, face restoration, etc. Additionally, we also looked briefly at the variants of the original U-Net model due to which the capabilities of U-Net have been expanded.
