
The RetinaNet model is a one-stage object detection model incorporating features such as Focal Loss, a Feature Pyramid Network (FPN), and various architectural improvements. These enhancements provide a unique balance between speed and accuracy, making RetinaNet a unique model.
Object detection, a core task in computer vision, involves finding and classifying objects within images or videos. This underpins applications like self-driving cars, security surveillance, and augmented reality.
About us: Viso Suite is the end-to-end computer vision infrastructure allowing ML teams to eliminate the need for point solutions. Viso Suite covers all stages in the application lifecycle from sourcing data to model training to deployment and beyond. To learn how Viso Suite helps enterprises easily integrate computer vision into their workflows, book a demo.
Two main approaches dominate object detection: One-Stage (like YOLO and SSD) and Two-Stage detectors (like R-CNN). Two-stage models propose likely object regions first, then classify and refine their bounding boxes. One-stage models bypass this step, predicting categories and bounding boxes directly from the image in one go.
Two-stage models (e.g., R-CNN) excel in accuracy and handling complex scenes. However, their processing time makes them less suitable for real-time tasks. On the other hand, one-stage models are fast but have limitations:
- Accuracy vs. Speed: High-accuracy models are computationally expensive, leading to slower processing. YOLO prioritizes speed, sacrificing some accuracy, particularly for small objects, compared to R-CNN variants.
- Class Imbalance: One-stage models treat detection as a regression problem. When “background” vastly outnumbers actual objects, the model becomes biased towards the background (negative) class.
- Anchors: YOLO and SSD rely on predefined anchor boxes with specific sizes and ratios. This can limit their ability to adapt to diverse object shapes and sizes.
What is RetinaNet?
RetinaNet is an object detection model that tries to overcome the limitations of object detection models mentioned above, specifically addressing the reduced accuracy in single-stage detectors. Despite RetinaNet being a Single-Stage detector it provides a unique balance between speed and accuracy.
It was introduced by Tsung-Yi Lin and the team in their 2017 paper titled “Focal Loss for Dense Object Detection.” Benchmark results on the MS COCO dataset show that the model achieves a good balance between precision (mAP) and speed (FPS), making it suitable for real-time applications.
RetinaNet incorporates the following features:
- Focal Loss for Object Detection: RetinaNet introduces Focal Loss to tackle the class imbalance problem during training. This is achieved by modifying the standard cross-entropy loss function to down-weight the loss assigned to well-classified examples. It gives less importance to easily classified objects and focuses more on hard, misclassified examples. This allows for increased accuracy without sacrificing speed.
- Feature Pyramid Network (FPN): RetinaNet incorporates an FPN as its backbone architecture. This enhances its ability to detect objects at different scales effectively.
- ResNet: FPN is built on top of a standard convolutional neural network (CNN) like ResNet.
- SubNetworks: These are specialized smaller networks that branch off the main feature extraction backbone. They are of two types:
- Classification Subnet
- Box Regression Subnet
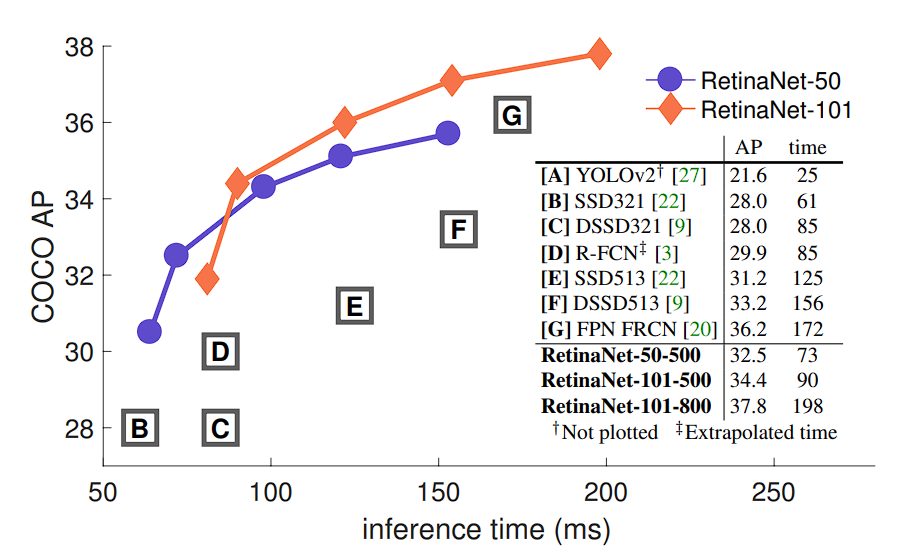
RetinaNet surpasses several object detectors, including one-stage and two-stage models, it forms an envelope of all the listed detectors.
Before we dive deeper into the architecture of RetinaNet, let’s look at some of the models before it, and the limitations and improvements they made over the previous models.
Overview of Object Detection Models
- R-CNN (Regions with CNN features) 2014:
- Fast R-CNN (2015):
- Improvements: Introduced ROI pooling to speed up processing by sharing computations across proposed regions.
Limitations: Although faster than R-CNN, it still relied on selective search for region proposals, which was a bottleneck.
- Improvements: Introduced ROI pooling to speed up processing by sharing computations across proposed regions.
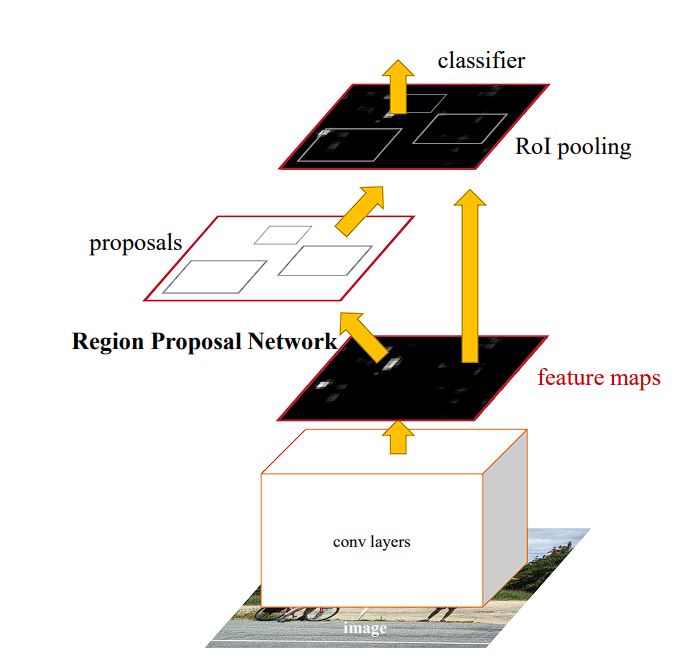
- Faster R-CNN (2015):
- Improvements: Integrated a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, improving both speed and accuracy.
- Limitations: While it was more efficient, the complexity of the model and the need for considerable computational resources limited its deployment in resource-constrained environments.

Faster R-CNN –source
- YOLO (You Only Look Once) (2016):
- Improvements: Extremely fast as it used a single neural network to predict bounding boxes and class probabilities directly from full images in one evaluation.
- Limitations: Struggled with small objects and objects in groups because of its spatial constraints on bounding box predictions.
YOLO Detection System –source
- SSD (Single Shot MultiBox Detector) (2016):
- Improvements: Attempted to balance speed and accuracy better than YOLO by using multiple feature maps at different resolutions to capture objects at various scales.
- Limitations: The accuracy was still not on par with the more complex models like Faster R-CNN, especially for smaller objects.

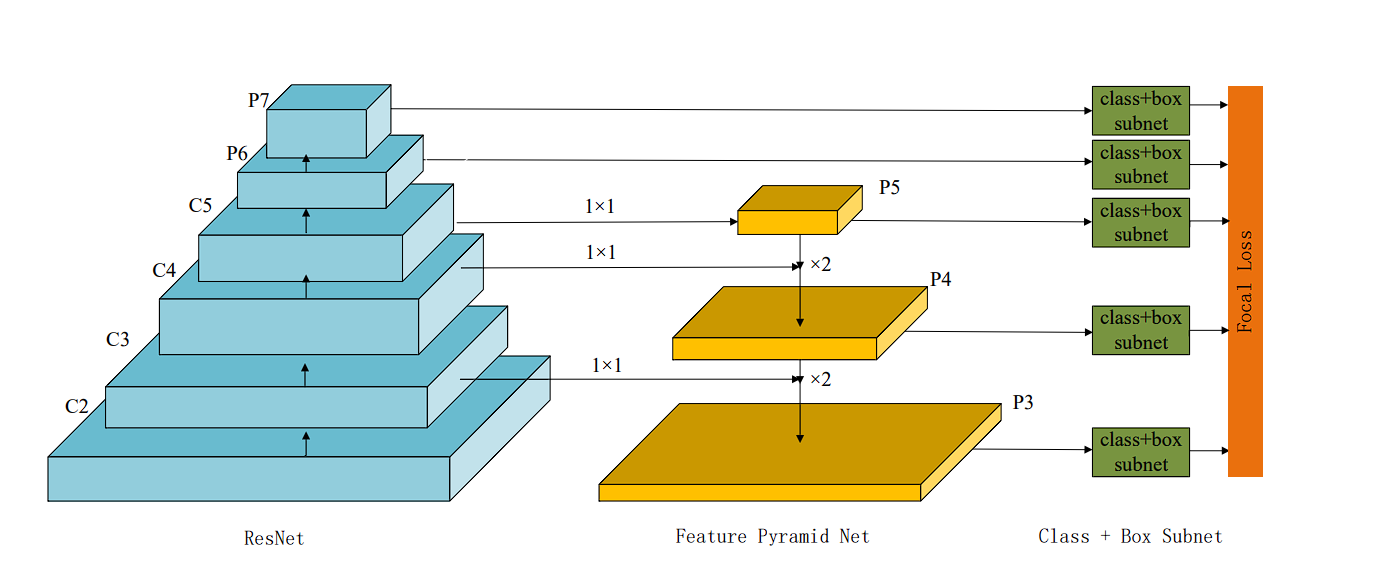
RetinaNet Architecture
What is ResNet?
ResNet (Residual Network), is a type of CNN architecture that solves the vanishing gradient problem, during training very deep neural networks.
As networks grow deeper, the network tends to suffer from a vanishing gradient. This is when the gradients used in training become so small that learning effectively stops due to activation functions squashing the gradients.
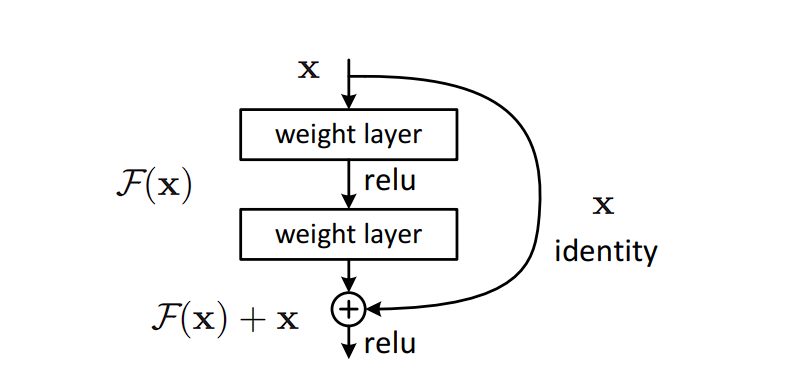
ResNet solves this problem by propagating the gradient throughout the network. The output from an earlier layer is added to the output of a later layer, helping to preserve the gradient sometimes lost in deeper networks. This allows for the training of networks with a depth of over 100 layers.
Feature Pyramid Network (FPN)
Detecting objects at different scales is challenging for object detection and image segmentation.
- Scale Variance: Objects of interest can vary significantly in size, from very small to very large, relative to the image size. Traditional CNNs might excel at recognizing medium-sized objects but often struggle with very large or very small objects due to fixed receptive field sizes.
- Loss of Detail in Deep Layers: As we go deeper into a CNN, the spatial resolution of the feature maps decreases due to pooling layers and strides in convolutions. This results in a loss of fine-grained details which are crucial for detecting small objects.
- Semantic Richness vs. Spatial Resolution: Typically, deeper layers in a CNN capture high-level semantic information but at a lower spatial resolution. Conversely, earlier layers preserve spatial details but contain less semantic information. Balancing these aspects is crucial for effective detection across different scales.
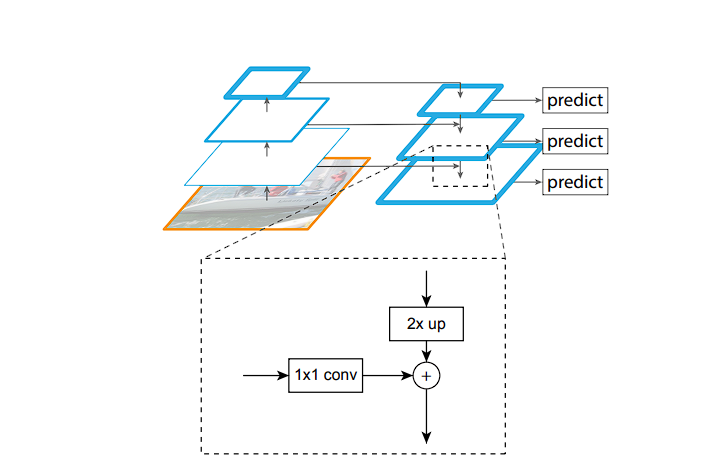
The FPN allows RetinaNet to detect objects at different scales effectively. Here is how it works.
FPN enhances the standard convolutional networks by creating a top-down architecture with lateral connections.
As the input image progresses through the network, the spatial resolution decreases (due to max pooling and convolutions), whereas the feature representation becomes richer and semantically stronger. The initial layers have detailed image features, the last layers have condensed representations.
- Top-Down Path: After reaching the deepest layer (smallest spatial resolution but highest abstraction), the FPN constructs a top-down pathway, gradually increasing spatial resolution by up-sampling feature maps from deeper (higher) layers in the network.
- Lateral Connections: RetinaNet leverages lateral connections to strengthen each upsampled map. These connections add features from the corresponding level of the backbone network. To ensure compatibility, 1×1 convolutions are used to reduce the channel dimensions of the backbone’s feature maps before they are incorporated into the upsampled maps
Loss Functions: Focal Loss
Object Detectors solve classification and regression problems simultaneously (class labels of the objects and their bounding box coordinates). The overall loss function is a weighted sum of the individual losses of each. By minimizing this combined loss, an object detector learns to accurately identify both the presence and the precise location of objects in images.
For the classification part of object detection cross-entropy loss is used. It measures the performance of a classification model whose output is a probability value between 0 and 1.
RetinaNet uses a modified version of cross-entropy loss. It is called Focal loss. Focal Loss addresses the issue of class imbalance in dense object detection tasks.
How does Focal Loss work?
Standard cross-entropy loss suffers in object detection because a large number of easy negative examples dominate the loss function. This overwhelms the model’s ability to learn from less frequent objects, leading to poor performance in detecting them.
Focal Loss modifies the standard cross-entropy loss by adding a focusing parameter that reduces the relative loss for well-classified examples (putting more focus on hard, misclassified examples), and a weighting factor to address class imbalance. The formula for Focal Loss is:
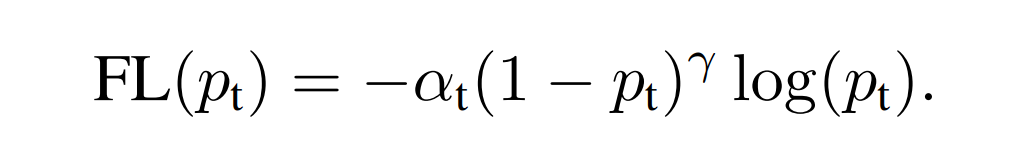
Here,
- pt is the model’s estimated probability for each class being the true class.
- αt is a balancing factor for the class (typically set to 0.25 within RetinaNet)
- γ is a focusing parameter to adjust the rate at which easy examples are down-weighted. It’s typically set to 2 in RetinaNet.
- (1−pt)γ reduces the loss contribution from easy examples and extends the range in which an example receives low loss.
Focal Loss helps improve the performance of object detection models, particularly in cases where there is a significant imbalance between foreground and background classes, by focusing training on hard negatives and giving more weight to rare classes.
This makes models trained with Focal Loss more effective in detecting objects across a wide range of sizes and class frequencies.
Subnetworks: Classification and Bounding Box Regression
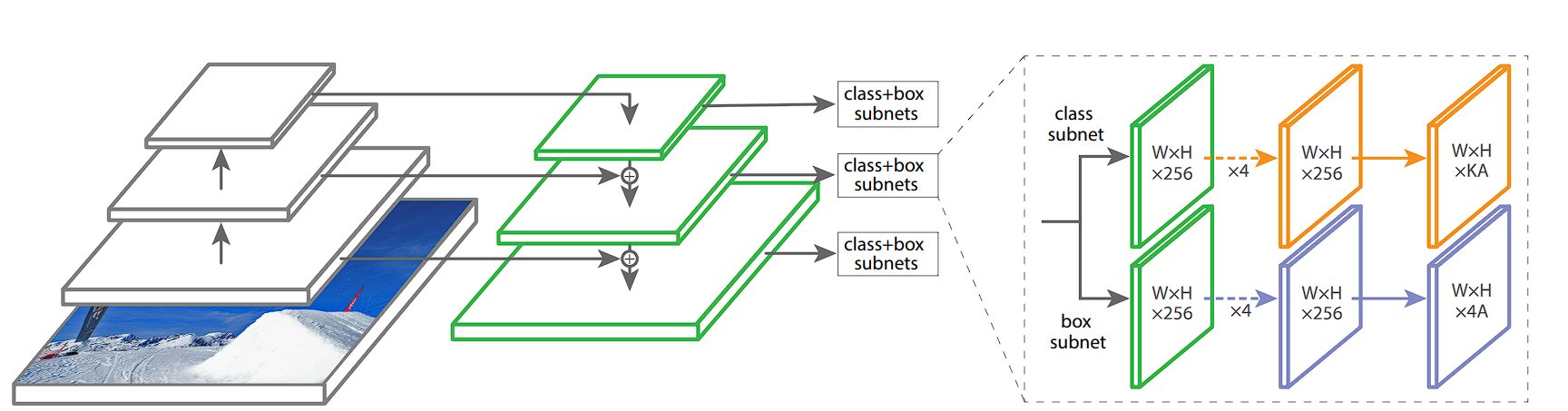
RetinaNet utilizes an FPN and two task-specific subnetworks linked to each level of the pyramid. The FPN takes a single-scale input and produces pyramid feature maps at different scales. Each level of the pyramid detects objects of different sizes.
Two Subnetworks
The two distinct subnetworks are attached to every level of the feature pyramid. Each level of the feature pyramid feeds into both subnetworks, allowing the model to make predictions at multiple scales and aspect ratios. The subnetworks consist of classification and bounding box regression networks:
- Classification Subnetwork: The classification subnetwork, a small fully convolutional network, attaches to each level of the feature pyramid. It consists of several convolutional layers followed by a sigmoid activation layer. This subnetwork predicts the probability of object presence at each spatial location for each anchor and each object class.
- Bounding Box Regression Subnetwork: This subnetwork predicts the offset adjustments for the anchors to better fit the actual object-bounding boxes. It consists of several convolutional layers but ends with a linear output layer. This subnetwork predicts four values for each anchor, representing the adjustments needed to transform the anchor into a bounding box that better encloses a detected object.
Applications of RetinaNet
- Small Target Detection: RetinaNet can be used for surveillance on roads to create safer cities. It has been applied for small target detection in aerial images. This paper discusses how the original RetinaNet was improved for detecting small objects, which gained a 6.21% improvement in accuracy.
- Ship-Detection in SAR Images: RetinaNet has a strong detection ability for hard targets due to focal loss. As a result, it has been used for ship detection in SAR images.
Ship Detection SAR images –source - Malaria Detection: RetinaNet has automated the process of malaria detection by identifying and counting normal and infected erythrocytes in blood smear images. RetinaNet with ResNet50 backbone achieved test results of Average Precision (AP) of 0.90, Average Recall of 0.78, and Average Accuracy of 0.71.

The Future of RetinaNet
In conclusion, RetinaNet has established itself as a great single-stage object detection model, offering high accuracy and efficiency. Its key innovation, the Focal Loss combined with FPN, and Two Subnetworks addresses the issues of class imbalances. These advancements have led to RetinaNet achieving state-of-the-art accuracy on various benchmarks.
However, there are a few areas in which it can make advancements in the future:
- Faster Inference Speeds: While RetinaNet already offers a balance between accuracy and speed, a lot of real-time applications such as autonomous driving and robotics require faster inference time. Research can explore efficient network architectures specifically designed for resource-constrained environments like mobile devices.
- Multi-task Learning: RetinaNet can be extended for tasks beyond object detection. By incorporating additional branches in the network, it can be useful for object segmentation, and pose estimation, all utilizing the performance of the model.
- Improved Backbone Architectures: RetinaNet relies on ResNet as its backbone architecture. However, newer and more efficient backbone architectures may achieve better performance.
