We use federated learning in the distributed model training on multiple edge devices without exchanging training data. Therefore, federated learning introduces a learning paradigm where statistical methods are trained at the edge in distributed networks.
Read about how federated learning works as well as its unique properties and associated challenges:
- Why we need Federated Learning
- What is Federated Learning?
- Core challenges and concepts of Federated Learning
About us: Viso.ai provides the leading end-to-end Computer Vision Platform Viso Suite. Global organizations use it to develop, deploy, and scale distributed Computer Vision Applications that run at the Edge. To learn more about Viso Suite, request a personal demo.
Why We Need Federated Learning
Big Data and Edge-Computing Trend
Connected devices, including mobile devices, wearables, and autonomous vehicles, generate massive amounts of data (Big Data). Associated computational power and privacy concerns result in the need for storing and processing local data. Thus, pushing the computation from the cloud to the edge.
Leveraging the power of Big Data requires Artificial Intelligence (AI). Deep Learning is effective in learning from complex data. For example, deep neural network architectures have outperformed humans when recognizing images from the popular ImageNet dataset.
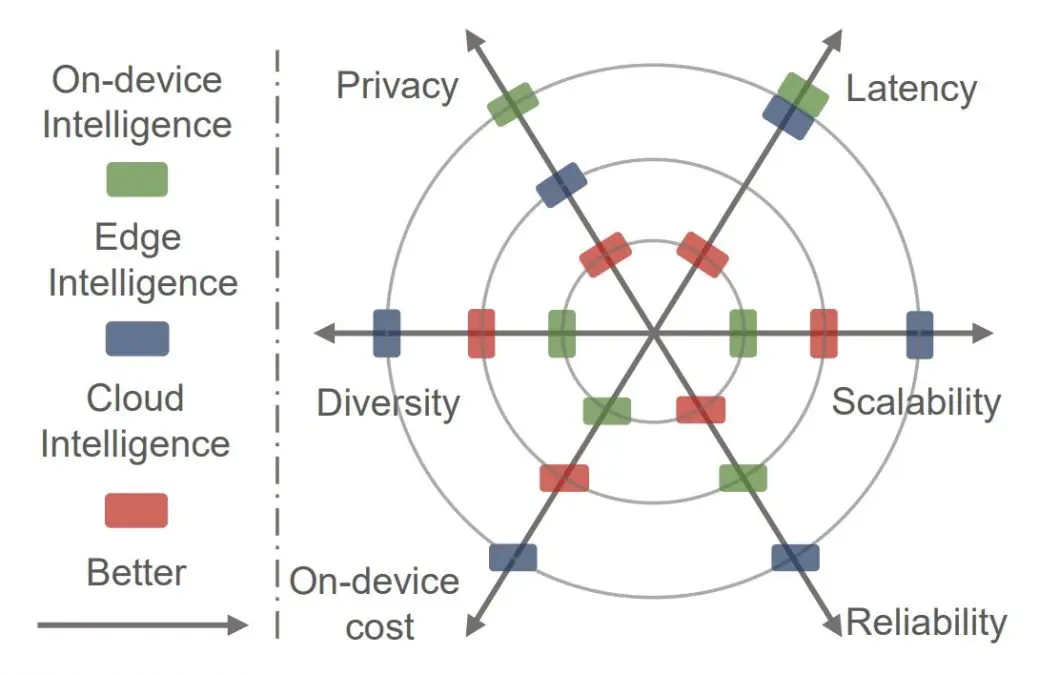
Edge Computing became the new paradigm, allowing for the adoption of computation-intense applications. Edge Intelligence or Edge AI is a combination of AI and Edge Computing. It enables machine learning algorithm deployment to the edge device generating data.
We refer to the combination of distributed and connected systems with ML as Artificial Intelligence of Things, or AIoT.
Most Edge Intelligence focuses on inference (running the AI model), assuming that training is performed in cloud data centers. This is mostly because of the high resource consumption of the training phase.
However, the growing computational capabilities and storage of connected edge devices enable methods for distributed training and deployment of machine learning models.
Need for Privacy-Preserving Deep Learning
Traditional machine learning approaches need to combine all data at one location, typically a cloud data center. However, this can sometimes violate the laws on user privacy and data confidentiality. Today, many governing bodies demand that technology companies treat sensitive data carefully according to user privacy laws. A prime example is the European Union’s General Data Protection Regulation (GDPR).
Federated learning is a privacy-preserving approach for training Deep Neural Network Models on data originated by multiple clients. Federated machine learning addresses this problem with solutions that combine:
- Distributed machine learning
- Cryptography and security
- Incentive mechanism design based on economic principles and game theory
Therefore, Federated learning could become the foundation of next-generation machine learning promoting responsible AI development and application.
What is Federated Learning
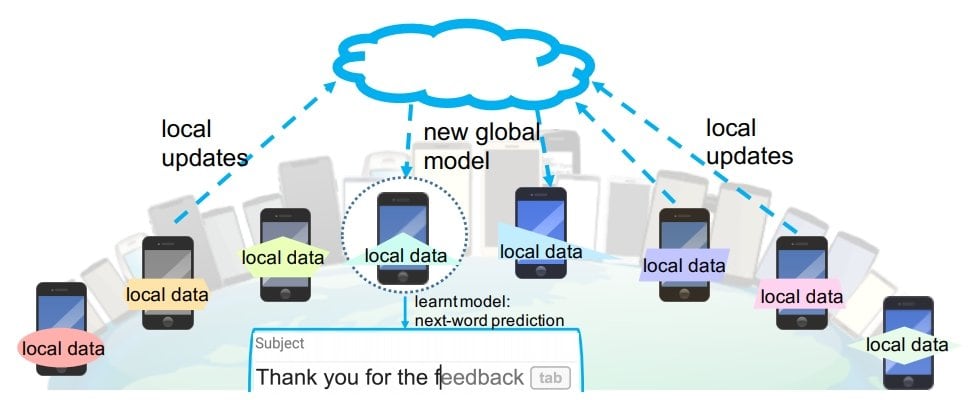
Federated learning (FL) is an ML setting where many clients (e.g., mobile devices) collaboratively train a model under the orchestration of a central server (e.g., service provider). This setting maintains the decentralization of annotated training data. Hence, machine learning algorithms, such as deep neural networks, are trained on multiple local datasets contained in local edge nodes.
Instead of aggregating the raw data to a central data center for training, federated learning leaves the raw data distributed on the client devices. It then trains a shared model on the server by aggregating locally computed updates.
Local models are locally trained on a specific subset or locality. This is as opposed to a model trained on the entire dataset.
Therefore, Federated learning can mitigate many systemic privacy risks and costs resulting from traditional, centralized machine learning approaches and centralized models.
Federated Learning Applications
Federated learning methods support privacy-sensitive applications with edge-distributed training data.
Some examples of federated learning applications include learning sentiment, semantic location, mobile phone activity, adapting to pedestrian behavior in autonomous vehicles, and predicting health events like heart attack risks from wearable devices.
- Smartphones. Statistical models power applications such as next-word prediction, face detection, and voice recognition by jointly learning user behavior across a large pool of mobile phones. However, users may not agree to share data for privacy purposes or to minimize bandwidth or battery usage of their phones. Federated learning can enable predictive features on smartphones without leaking PII or diminishing user experience.
- Organizations. In federated learning, organizations or institutions are viewed as “devices.” For example, hospitals are organizations that contain a large amount of patient data for predictive healthcare applications. Meanwhile, hospitals operating under strict privacy practices can face legal, administrative, or ethical constraints requiring local data. Federated learning can reduce strain on the network and enable private learning between various devices/organizations.
- Internet of Things. Modern IoT networks use sensors to collect and react to incoming data in real time. A fleet of autonomous vehicles may require an up-to-date model of traffic, construction, or pedestrian behavior. Building aggregate models in these scenarios may be difficult because of privacy concerns and the limited device connectivity. Federated learning enables model training to efficiently adapt to system changes while maintaining user privacy.
Core Challenges of Federated Learning
The implementation of Federated Learning depends on a set of key challenges:
- Efficient Communication across the federated network
- Managing heterogeneous systems in the same networks
- Statistical heterogeneity of data in federated networks
- Privacy concerns and privacy-preserving methods
Communication-Efficiency
Communication is a key bottleneck to consider when developing methods for federated networks. Federated networks can potentially include a massive number of devices, for example, millions of smartphones. For this reason, communication in the network can be slower than local computation by many orders of magnitude.
Therefore, federated learning depends on communication-efficient methods iteratively sending small messages or model updates as part of the distributed training process. This is instead of sending the entire dataset over the network. The two main goals to further reduce communication are:
- Reducing the total number of communication rounds
- Reducing the size of transmitted messages at each round.
The following are general concepts that aim to achieve communication-efficient distributed learning methods:
- Local updating methods: Allow for a variable number of local updates applied on each machine in parallel at each communication round. Thus, the goal of local updating methods is to reduce the total number of communication rounds.
- Model compression schemes: Sparsification, subsampling, and quantization can significantly reduce the size of messages communicated at each update round.
- Decentralized training: In federated learning, a server connects with all remote devices. Decentralized topologies are an alternative when communication to the server becomes a bottleneck. Especially when operating in low bandwidth or high latency networks.
Systems Heterogeneity
The storage, computational, and communication capabilities of the devices that are part of a federated network may differ significantly. Differences usually occur because of variability in hardware (CPU, memory), network connectivity (3G, 4G, 5G, wifi), and power supply (battery level).
Additionally, only a small fraction of the devices may be active at once. Each device may be unreliable as edge devices can sometimes drop out because of connectivity or energy constraints. Therefore, fault tolerance is important as participating devices may drop out before finishing the given training iteration.
Therefore, we must develop federated learning methods so that they:
- Anticipate a low amount of participation
- Tolerate heterogeneous hardware
- Are robust to dropped devices in the network
Some key directions to handle systems heterogeneity are:
- Asynchronous communication: Used to parallelize iterative optimization algorithms. Asynchronous schemes are an attractive approach to mitigating stragglers in heterogeneous environments.
- Active device sampling: Typically, only a small subset of devices participate in each round of training. Therefore, you can actively select participating devices at each round. The goal is to aggregate as many device updates as possible within a pre-defined time window.
- Fault tolerance: A practical approach is to ignore device failure. This may lead to bias in the device sampling scheme if the failed devices have specific data characteristics. Coded computation is another option to tolerate device failures by introducing algorithmic redundancy.
Statistical Heterogeneity
Devices frequently generate and collect data in a non-identically distributed manner across the network. For example, mobile phone users have varied uses of language in the context of a next-word prediction task.
Also, the number of data points across devices may vary significantly. And, there may be an underlying structure present that captures the relationship between devices and their associated distributions. This data generation paradigm:
- Violates frequently used independent and identically distributed (I.I.D.) assumptions in distributed optimization
- Increases the likelihood of stragglers
- May add complexity to modeling, analyzing, and evaluation
Challenges arise when training federated models from data not identically distributed across devices. This is observable in both modeling the data and analyzing the convergence behavior of associated training procedures.
Privacy Concerns
Privacy concerns often motivate the need to keep raw user data on each device locally in federated settings. However, sharing other information as part of the training process can also potentially reveal sensitive information.
Recently methods aim to enhance the privacy of federated learning using secure multiparty computation (SMC) or differential privacy. However, those methods usually provide privacy at the cost of reduced model performance or system efficiency. Therefore, balancing these trade-offs is a considerable challenge in realizing private federated learning systems.
- Differential Privacy is a popular privacy approach because of its strong information-theoretic guarantees, algorithmic simplicity, and comparably small systems overhead. A randomized mechanism is differentially private if changing an input element won’t overly influence the output distribution. Therefore, it is not possible to conclude whether or not a specific sample is used in the learning process. Furthermore, there is an inherent trade-off between differential privacy and model accuracy. Adding more noise results in greater privacy but could significantly compromise accuracy.
- Homomorphic Encryption secures the learning process by computing encrypted data. However, it has currently been applied in limited settings, e.g., training linear models or involving only a few entities.
- Secure multiparty computation (SMC) or secure function evaluation (SFE) can perform privacy-preserving learning with sensitive datasets distributed across different data owners. Those protocols enable multiple parties to collaboratively learn and compute an agreed-upon function. We can do this without leaking raw input information from any party except for what we infer from the output. SMC is a lossless method and can retain the original accuracy with a high privacy guarantee. To achieve even stronger privacy guarantees, we can combine SMC with differential privacy.
Privacy-preserving methods have to offer rigorous privacy guarantees without overly compromising accuracy. Therefore, such methods must be computationally cheap, communication-efficient, and tolerant to dropped devices.
Current implementations of privacy-preserving federated learning typically build around classical cryptographic protocols such as SMC and differential privacy. However, SMC techniques impose significant performance overheads, and their application to privacy-preserving deep learning remains an open problem.

What’s Next for Federated Learning?
Federated learning is a useful tool for edge computing and privacy preservation. To learn more about related topics, we recommend the following articles:
- Everything you need to know about Edge AI
- Read about Deep Reinforcement Learning
- Read about Self-Supervised Learning and Supervised vs. Unsupervised Learning
- Learn about Edge Intelligence to deploy Deep Learning models
- Active Learning in Computer Vision
References
- Advances and Open Problems in Federated Learning – Source
- Federated Learning: Challenges, Methods, and Future Directions – Source
Viso Suite
Viso Suite is the only infrastructure that provides true end-to-end management of computer vision applications. Enterprises across industry lines trust Viso Suite with their sensitive data. Holding an ISO27001 certificate and performing military-grade encryption, Viso Suite ensures all user data is kept secure. To learn how Viso Suite optimizes business processes, book a demo with one of our team members.