Object detection is an important task in computer vision that identifies and locates where an object is in an image, by drawing bounding boxes around the detected objects. The importance of object detection can’t be stated enough. It allows for applications in a variety of fields, e.g., it powers self-driving vehicles, drones, disease detection, and digital security surveillance.
In this blog, we will look deeply into FCOS, an innovative and popular object detection model applied to various fields. But before diving into the innovations brought by FCOS, it is important to understand the types of object detection models available.
About us: We’ve built the Viso Suite infrastructure for enterprise computer vision applications. In a single interface, we deliver the full process of application development, deployment, and management. To learn more, book a demo with our team.
Types of Object Detection Models
Object detection models can be divided into two categories, one-stage and two-stage detectors.
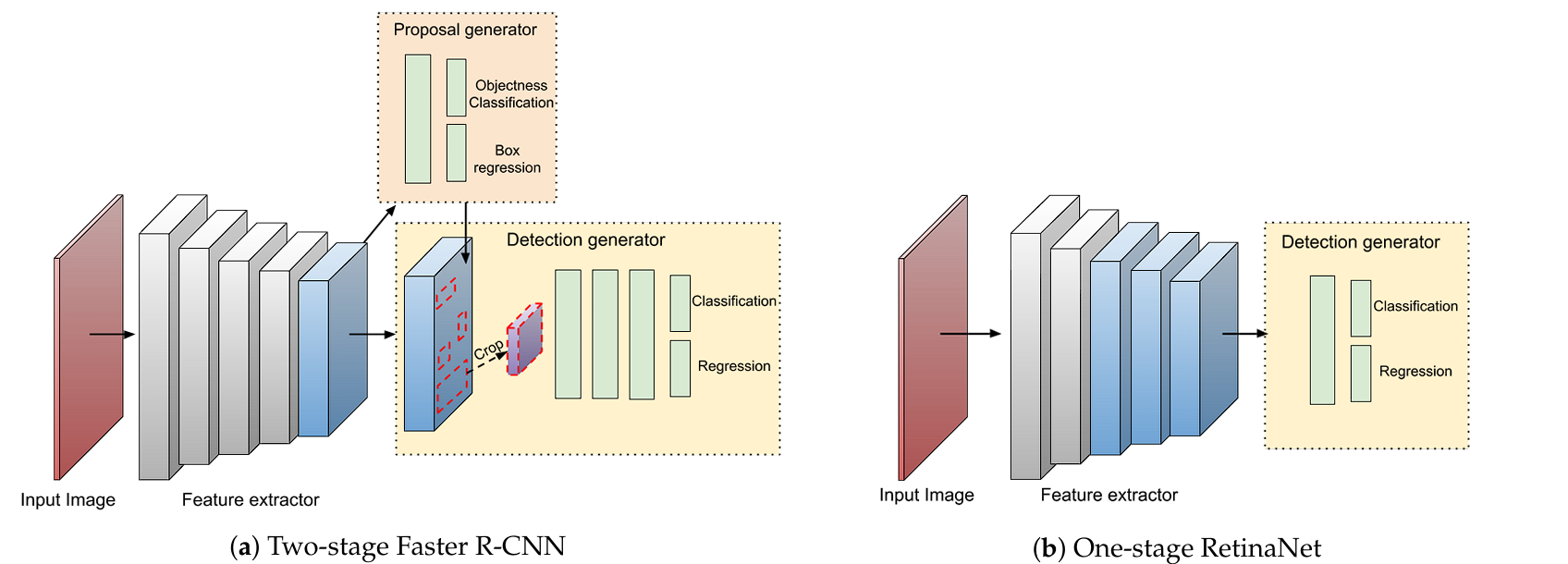
Two-Stage Detectors
Two-stage detectors, such as R-CNN, Fast R-CNN, and Faster R-CNN, divide the task of object detection into a two-step process:
- Region Proposal: In the first stage, the model generates a set of region proposals that are likely to contain objects. This is done using methods like selective search (R-CNN) or a Region Proposal Network (RPN) (Faster R-CNN).
- Classification and Refinement: In the second stage, the proposals are classified into object categories and refined to improve the accuracy of the bounding boxes.
The multi-stage pipeline is slower, more complex, and can be challenging to implement and optimize in comparison to single-stage detectors. However, these two-stage detectors are usually more robust and achieve higher accuracy.
One-Stage Detectors
One-stage detectors, such as FCOS, YOLO (You Only Look Once), and SSD (Single Shot Multi-Box Detector) eliminate the need for regional proposals. The model in a single pass directly predicts class probabilities and bounding box coordinates from the input image.
This results in one-stage detectors being simpler and easier to implement compared to two-stage methods, also the one-stage detectors are significantly faster, allowing for real-time applications.
Despite their speed, they are usually less accurate and use pre-made anchors for detection. However, FCOS has reduced the accuracy gap compared with two-stage detectors and completely avoids the use of anchors.
What is FCOS?
FCOS (Fully Convolutional One-Stage Object Detection) is an object detection model that drops the use of predefined anchor box methods. Instead, it directly predicts the locations and sizes of objects in an image using a fully convolutional network.
This anchor-free approach in this state-of-the-art object detection model has resulted in the reduction of computational complexity and increased performance gap. Moreover, FCOS outperforms its anchor-based counterparts.
What are Anchors?
In single-stage object detection models, anchors are pre-defined bounding boxes used during the training and detection (inference) process to predict the locations and sizes of objects in an image.
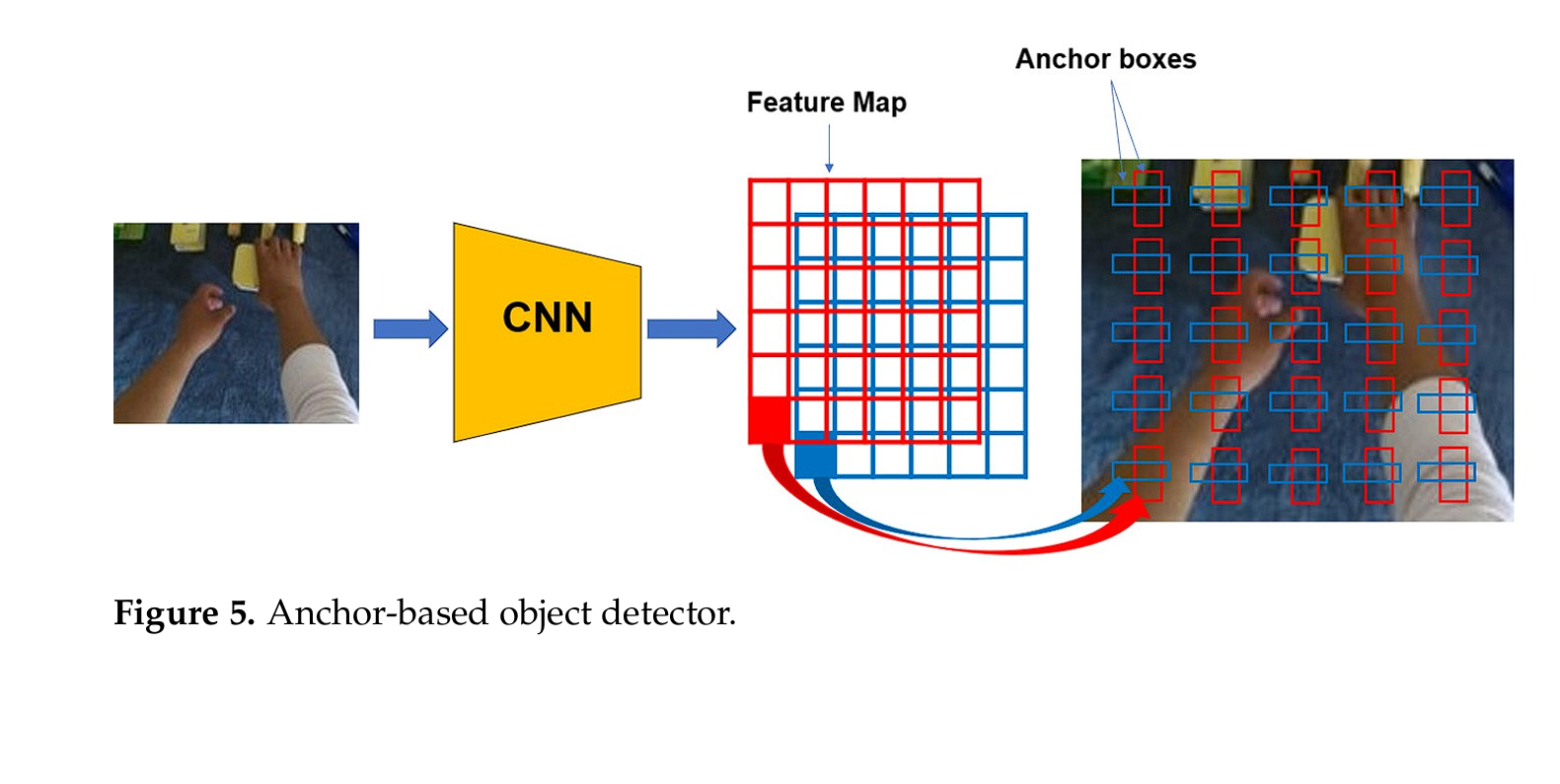
Popular models such as YOLO and SSD use anchor boxes for direct prediction, which leads to limitations in handling varying object sizes and shapes, and also reduces the model’s robustness and efficiency.
Limitations of Anchors
- Complexity: Anchor-based detectors depend on numerous anchor boxes of different sizes and aspect ratios at various locations in the image. This increases the complexity of the detection pipeline, as it requires the designing of anchors for various objects.
- Computation related to Anchors: Anchor-based detectors utilize a large number of anchor boxes at different locations, scales, and aspect ratios during both training and inference. This is computationally intensive and time-consuming
- Challenges in Anchor Design: Designing appropriate anchor boxes is difficult and leads to the model being capable for the specific dataset only. Poorly designed anchors can result in reduced performance.
- Imbalance Issues: The large number of negative sample anchors (anchors that do not overlap significantly with any ground truth object) compared to positive anchors can lead to an imbalance during training. This can make the training process less stable and harder to converge.
How Anchor-Free Detection Works
An anchor-free object detection model such as FCOS takes advantage of all points in a ground truth bounding box to predict the bounding boxes. In essence, it works by treating object detection as a per-pixel prediction task. For each pixel on the feature map, FCOS predicts:
- Object Presence: A confidence score indicating whether an object is present at that location.
- Offsets: The distances from the point to the object’s bounding box edges (top, bottom, left, right).
- Class Scores: The class probabilities for the object present at that location.
By directly predicting these values, FCOS completely avoids the complicated process of designing anchor boxes, simplifying the detection process and enhancing computational efficiency.
FCOS Architecture
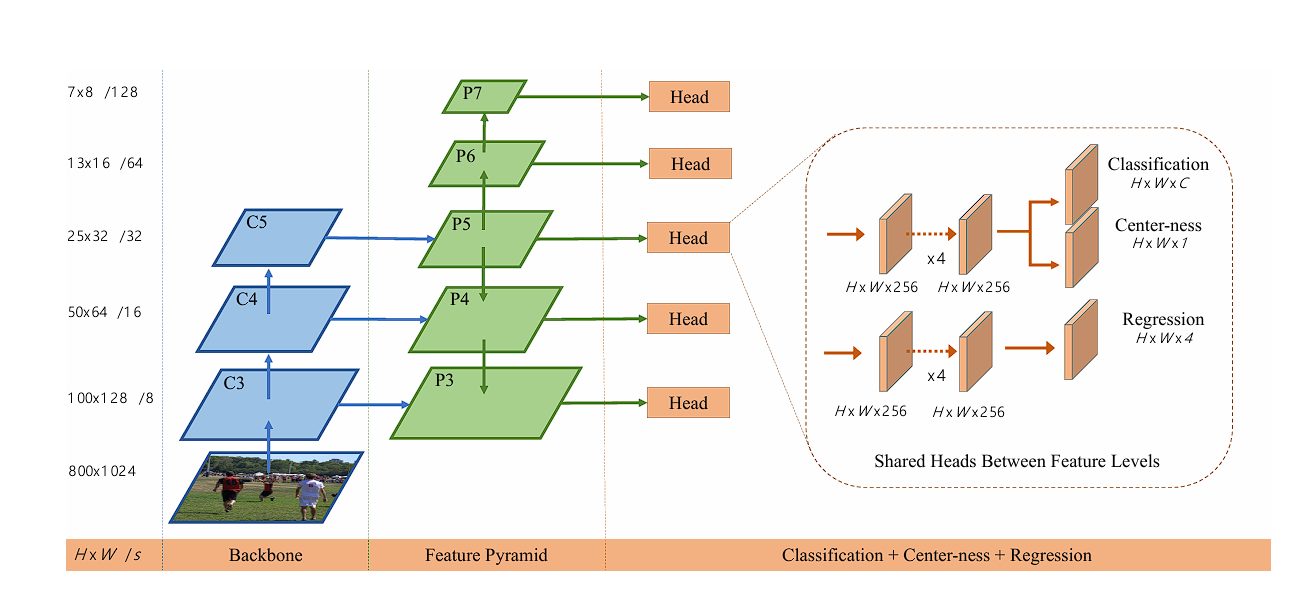
Backbone Network
The backbone network works as the feature extractor, by transforming images into rich feature maps that will be used in the later layers for detection purposes in the architecture of FCOS. In the original published research paper on FCOS, the researchers used ResNet and ResNeXt as the backbone for the model.
The backbone network processes the input image through multiple layers of convolutions, pooling, and non-linear activations. Each layer captures increasingly abstract and complex features, ranging from simple edges and textures in the early layers to entire object parts and semantic concepts in the deeper layers.
The feature maps produced by the backbone are then fed into subsequent layers that predict object locations, sizes, and classes. The backbone network’s output ensures that the features used for prediction are both spatially precise and semantically rich, improving the accuracy and robustness of the detector.
ResNet (Residual Networks)
ResNet uses residual connections or shortcuts that skip one or more layers, which helps to tackle the vanishing gradient problem. This allows researchers to build deeper models, such as ResNet-50, ResNet-101, and ResNet-152 (it has a massive 152 layers).
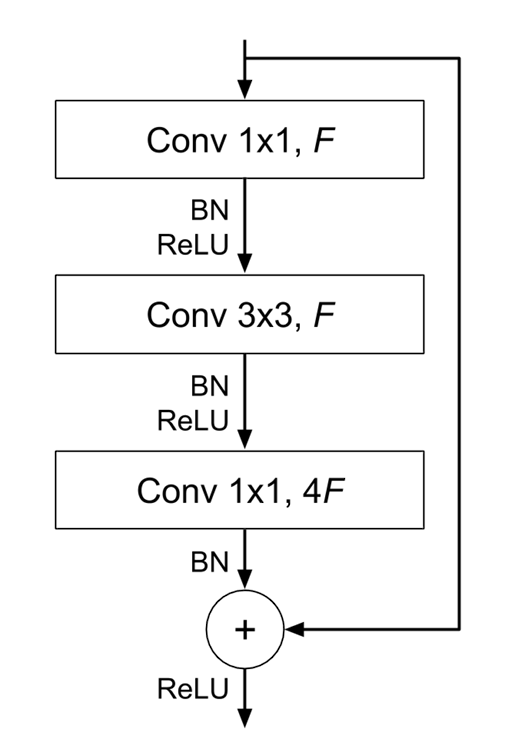
A residual connection connects the output of one earlier convolutional layer to the input of another future convolutional layer, several layers later into the model (as a result several CNN layers are skipped). This allows for the gradients to flow directly through the network during backpropagation, helping with the vanishing gradient problem (a major issue with training very deep neural networks).
In the research paper on FCOS, the researchers also used a Feature Pyramid Network (FPN).
What is FPN?
A Feature Pyramid Network (FPN) enhances the ability of CNNs to detect objects at multiple scales. As discussed above, the initial layers detect edges and shapes, while deeper layers capture parts of an image and other complex features. FPN creates an outlet at both the initial layers and deeper layers. This results in a model capable of detecting objects of various sizes and scales.
By combining features from different levels, the network better understands the context. This allows for better separation of objects and background clutter.
Moreover, small objects are difficult to detect because they are not represented in lower-resolution feature maps produced in deeper layers (feature map resolution decreases due to max pooling and convolutions). The high-resolution feature maps from early layers in FPN allow the detector to identify and localize small objects.
Multi-Level Prediction Heads
In the FCOS, the prediction head is responsible for making the final object detection predictions. In FCOS, there are three different heads are responsible for different tasks.
These heads operate on the feature maps produced by the backbone network. The three heads are:
Classification Head
The classification head predicts the object class probabilities at each location in the feature map. The output is a grid where each cell contains scores for all possible object classes, indicating the likelihood that an object of a particular class is present at that location.
Regression Head

The regression head precuts the bounding box coordinated with the object detected at each location on the feature map.
This head outputs four values for the bounding box coordinates (left, right, top, bottom). By using this regression head, FCOS can detect objects without the need for anchor boxes.
For each point on the feature map, FCOS predicts four distances:
- l: Distance from the point to the left boundary of the object.
- t: Distance from the point to the top boundary of the object.
- r: Distance from the point to the right boundary of the object.
- b: Distance from the point to the bottom boundary of the object.
We can derive the coordinates of the predicted bounding box as:
bbox𝑥1=𝑝𝑥−𝑙
bbox𝑦1=𝑝𝑦−𝑡
bbox𝑥2=𝑝𝑥+𝑟
bbox𝑦2=𝑝𝑦+𝑏
Where (𝑝𝑥,𝑝𝑦) are the coordinates of the point on the feature map.
Center-ness Head

This head predicts a score of 0 and 1 which indicates how likely the current location is at the center of the detected object. This score is then used to down-weight the bounding box prediction for locations far from the center of an object, as they are unreliable and likely false predictions.
We calculate this as:
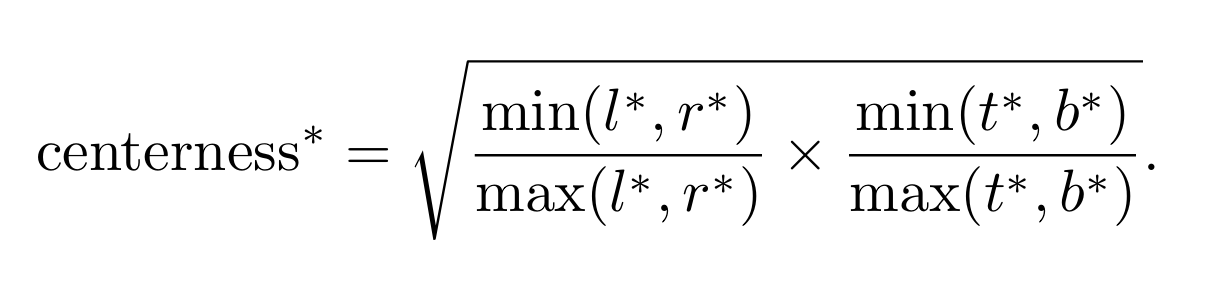
Here l, r, t, and b are the distances from the location to the left, right, top, and bottom boundaries of the bounding box, respectively. This score ranges between 0 and 1, with higher values that indicate points closer to the center of the object. It is found using binary cross entropy loss (BCE).
These three prediction heads work collaboratively to perform object detection:
- Classification Head: This predicts the probability of each class label at each location.
- Regression Head: This head gives the precise bounding box coordinates for objects at each location, indicating exactly where the object is located within the image.
- Center-ness Head: This head enhances and corrects the prediction made by the regression head, using the center-ness score, which helps in suppressing low-quality bounding box predictions (as bounding boxes far from the center of the object are likely to be false).
During training, the outputs from these heads are combined. The bounding boxes predicted by the regression head are adjusted based on the center-ness scores. This is achieved by multiplying the center-ness scores with prediction scores, which goes into the loss function. This eradicates the low-quality and off-the-target bounding boxes.
The Loss Function
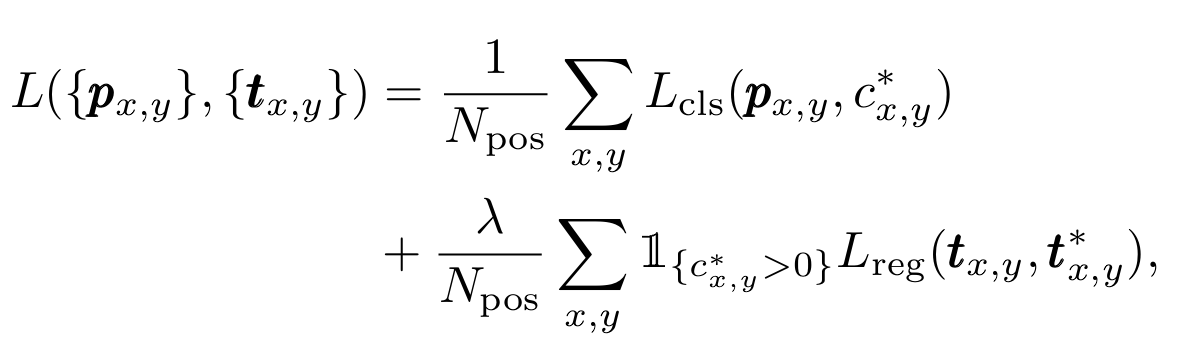
Total loss is the sum of classification and regression loss terms, with classification loss Lcls being focal loss.
Conclusion
In this blog, we explored FCOS (Fully Convolutional One-Stage Object Detection) which is a fully convolutional one-stage object detector that directly predicts object bounding boxes without the need for predefined anchors, one-stage object detectors such as YOLO and SSD, that heavily relies on anchors. Due to the anchor-less design, the model completely avoids the complicated computation related to anchor boxes such as the IOU loss computation and matching between the anchor boxes and ground-truth boxes during training.
The FCOS model architecture uses the ResNet backbone combined with prediction heads for classification, regression, and center-ness score (to adjust the bounding box coordinates predicted by the regression head). The backbone extracts hierarchical features from the input image, while the prediction heads generate dense object predictions on feature maps.
Moreover, the FCOS model lays an extremely important foundation for future research works on improving object detection models.
Read our other blogs to enhance your knowledge of computer vision tasks:
- Image Fusion in Computer Vision
- Object Localization and Image Localization
- Decoding Movement: Spatio-Temporal Action Recognition
- What is Pattern Recognition? A Gentle Introduction
- Bias Detection in Computer Vision: A Comprehensive Guide
- DETR: End-to-End Object Detection With Transformers
Using Enterprise-grade Computer Vision
Viso Suite is the only fully end-to-end computer vision infrastructure. By developing, deploying, and securing applications in one place, Viso Suite omits the need for using point solutions. To learn more about Viso Suite for your business challenges, book a demo with our team.