
Generative AI, the infamous category of artificial intelligence models that can craft new content like images, text, or code has taken the world by storm in recent years. These models have shown remarkable potential in various fields, from art and entertainment to healthcare and finance, transforming how we create and interact with digital content.
In this comprehensive guide, we will delve into the inner workings of those models, exploring different types, applications, challenges, and the future they hold.
About us: viso.ai provides the leading end-to-end Computer Vision Platform Viso Suite. Global organizations like IKEA and DHL use it to build, deploy, and scale all computer vision applications in one place, with automated infrastructure. Get a personal demo.
Understanding Generative AI
Generative AI refers to the class of AI models capable of generating new content depending on an input. Text-to-image for example, refers to the ability of the model to generate images from a text prompt. Text-to-text models can produce text output based on a text prompt. Many more input-output combinations exist for generative models. Other tasks include text-to-video, audio-to-audio, image-to-image, and more.
Generative models underwent many developments, reaching an impressive level of creativity and realism. Let’s explore what generative AI is at its core, and how it works.
What Are Generative Models?
At their core, generative models are a class of machine-learning models designed to learn the underlying patterns in data. This data can be audio, text, or visuals like images and videos. When the model learns those patterns and their distribution, it allows to generate new data.
However, the way this works contrasts with discriminative models, which are the types of AI models trained for tasks like regression, classification, clustering, and more. The key difference is their ability to generate, or synthesize new data.
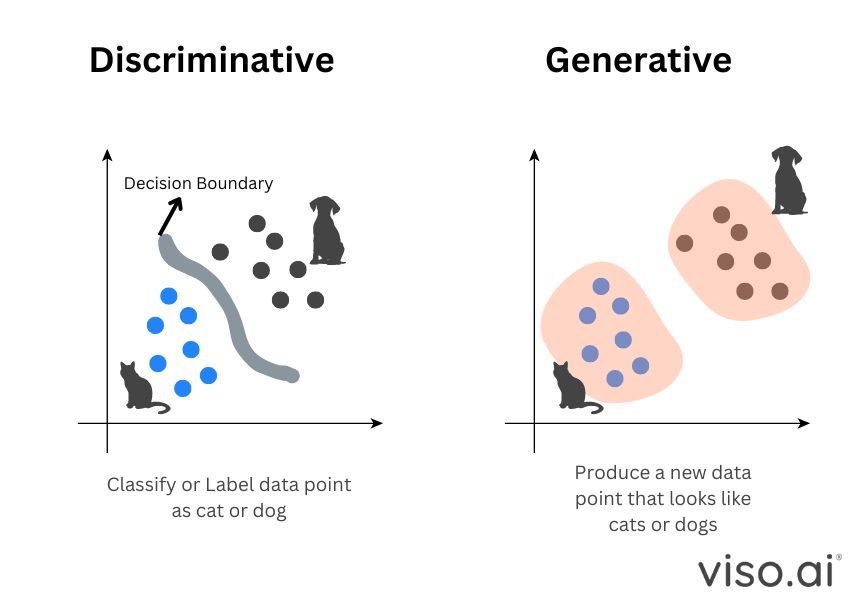
Consider the x and y axis as a space where data points exist, each data point is either a cat or a dog. A discriminative model task is to predict what each data point is, even with new data. On the other hand, the generative AI task is to create new data points that look like the existing ones.
Discriminative models include a wide range of models, like Convolutional Neural Networks (CNNs), Deep Neural Networks (DNNs), Support Vector Machines (SVMs), or even simpler models like random forests. These models are concerned with tasks like classification, regression, segmentation, and detection.
However, generative AI models are a different class of deep learning. Those models try to understand the distribution of data points to generate similar-looking points. This process depends on the probabilistic distribution of the data creating realistic data. Next, let’s take a deeper look into how generative AI works.
How do Generative Models Work?
Generative AI aims to synthesize new data based on the pre training data. It does this by learning the joint probability of the data. For instance, for a data X with labels Y, the model will learn P(x,y) or P(x) if there are no labels.
For example, in Natural Language Processing (NLP), the model works by predicting the next word in a sequence. This type of probability learning is what distinguishes generative models. What happens in generative AI is it learns the distribution of the data, and then you sample a new data point from the distribution, that is when the model generates a realistic output that represents that learned distribution.
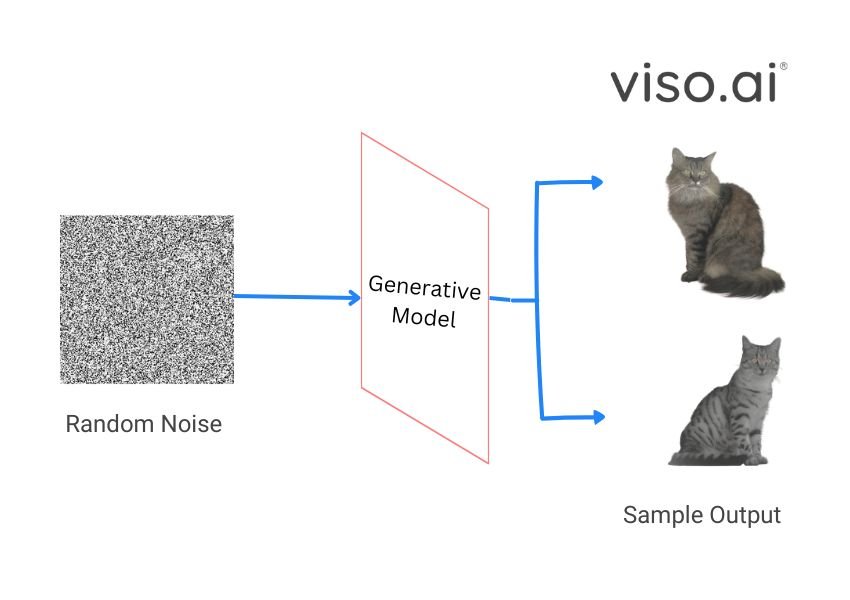
For a generative model to generate samples, it needs a training data set. Each data point would have its features, pixel values for image data, or vocabulary set for text. The illustration above shows how a generative model takes random noise from a latent space as input. This random noise sampled from the latent space is a new data point representing an image from which the model will generate the image.
Most visual generative models use this method where a model is trained by adding noise and then denoising the image to create it back. At inference, the model would either sample a random point in the space and denoise it or depend on the user input to choose a specific point.
On the other hand, the text generative model uses tokens, those tokens are like the noise we use for images. Text is encoded into tokens and tokens are decoded into text. In NLP this process is used to predict the next word in a sentence.
Types of Generative AI Models
Generative AI is a rapidly growing field with various models emerging, each with its own unique strengths and ideal use cases. At their core, generative models work by capturing the patterns and structure within data, whether it’s images, text, music, or any other form. By understanding these patterns, they can then generate new, similar data that often looks realistic.
However, despite this common working principle, different generative models vary significantly in their architecture, training, capabilities, and variations. We will explore the most impactful types of generative AI models and uncover how they work.
Variational Autoencoders (VAEs)
One of the earliest generative models is the Variational Autoencoders (VAEs), which are based on the simple encoder-decoder architecture of autoencoders. Autoencoders are a type of neural network that simply copies the input to the output. A variational autoencoder takes this a step further.
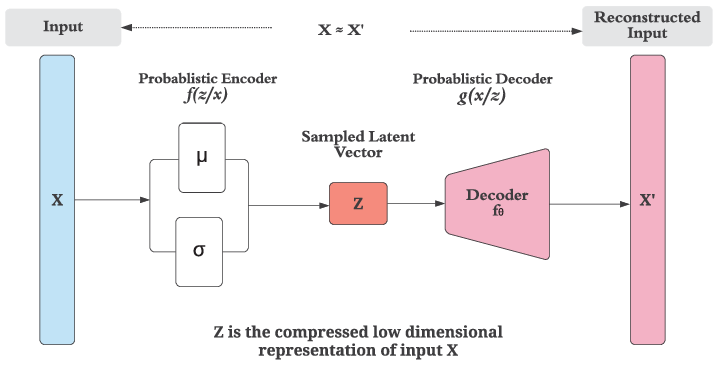
Using an encoder, an autoencoder encodes image (X) into a lower dimensional latent representation. The decoder then decodes the representation back to an image. The learning process of an autoencoder involves learning how to compress the data while minimizing the reconstruction error. This is useful when we want to denoise images, feature extraction, and image reconstruction.
However, VAEs are a probabilistic take on autoencoders, mapping the image to a probabilistic distribution. This gives VAEs the ability for image generation, although they produce blurry and less diverse results, and they can be resource-extensive for high-resolution images.
Generative Adversarial Networks (GANs)
Generative adversarial networks (GANs) are a popular type of generative AI that is mostly used for various types of image generation. The adversarial part comes from the dual neural network architecture of GANs. This deep learning architecture uses two neural networks that compete against each other, the generator and discriminator.
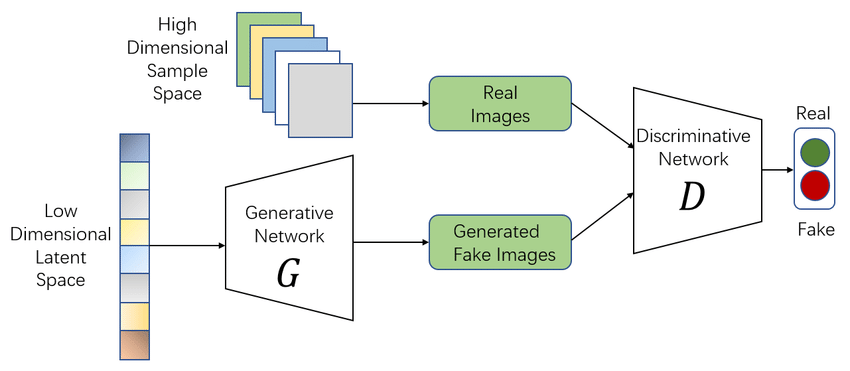
Both the discriminator and generator learn the features of the dataset, but the discriminator also learns to distinguish between the features. The generator then adds random noise to the image representations to generate a new image. The generated image is sent to the discriminator, which identifies if the image is fake or real, and gives guidance to the generator to modify the noise vector. The final step is when the discriminator is finally not able to distinguish between the generated images and the training data.
There are many GAN variations each with its strengths, below are some of the variations:
However, GANs are notorious for their difficulty in training, as they can often suffer from mode collapse or instability, thus many variations are trying to address those challenges.
Transformer-Based Models
The infamous Transformer architecture introduced in the “Attention is all you need” paper by Google has changed the generative AI field. This architecture is widely used for language models bringing state-of-the-art performance and results.
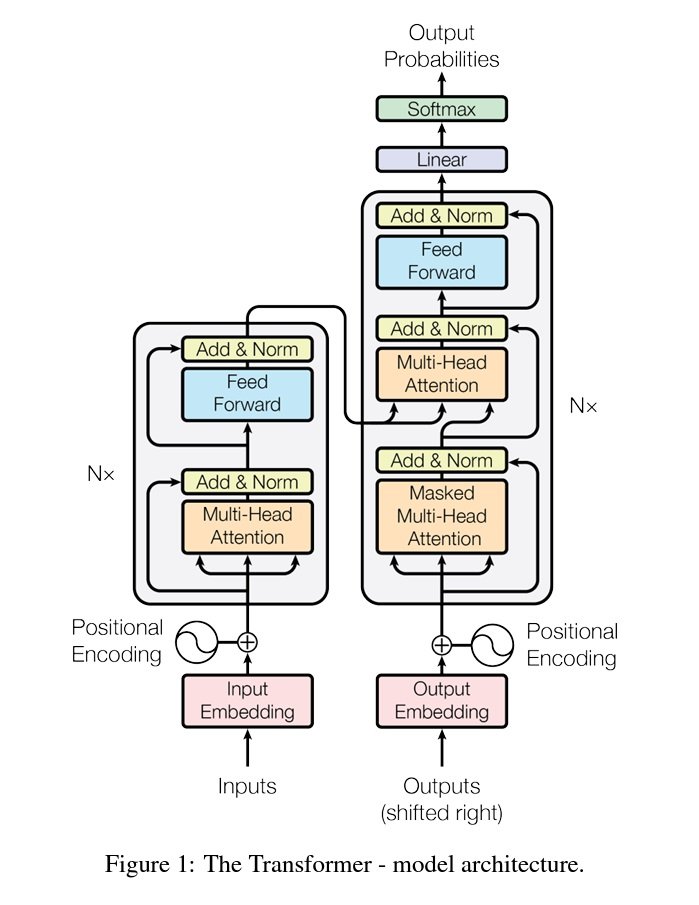
Previous NLP techniques involved using Recurrent Neural Networks (RNNs) and CNNs to predict the next word. Transformers used an encoder-decoder architecture, with the addition of self-attention mechanisms which made a huge difference. This self-attention mechanism allows the model to weigh the importance of different words in a sentence, or elements in an image when generating a prediction. Transformers employ multiple self-attention mechanisms called heads allowing it to learn relationships and long-range dependencies.
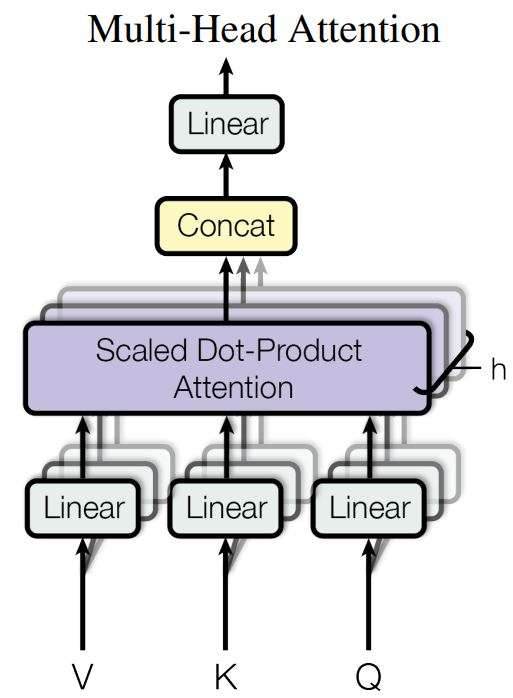
This architecture is used in many models now, for example, GPT models use a transformer-based architecture for text generation. Other models like BLIP which is a multimodal AI, employ a transformer-based architecture used for tasks like Visual Question Answering (VQA), or image captioning. Furthermore, researchers found that larger transformer models performed better such as Mega Transformer which has billions of parameters.
However, Transformer generative AI models need a huge amount of data and a lot of resources to train, as well as have other considerations like bias and explainability. Explainable AI (XAI) methods are working to make the Transformer decision-making processes more transparent.
Diffusion Models
Diffusion models are one of the newest models in generative AI. Those models use the same basic concept of early GAN and VAE models. These models Achieved state-of-the-art performance through innovative techniques, often leveraging a U-Net architecture to facilitate the denoising process.
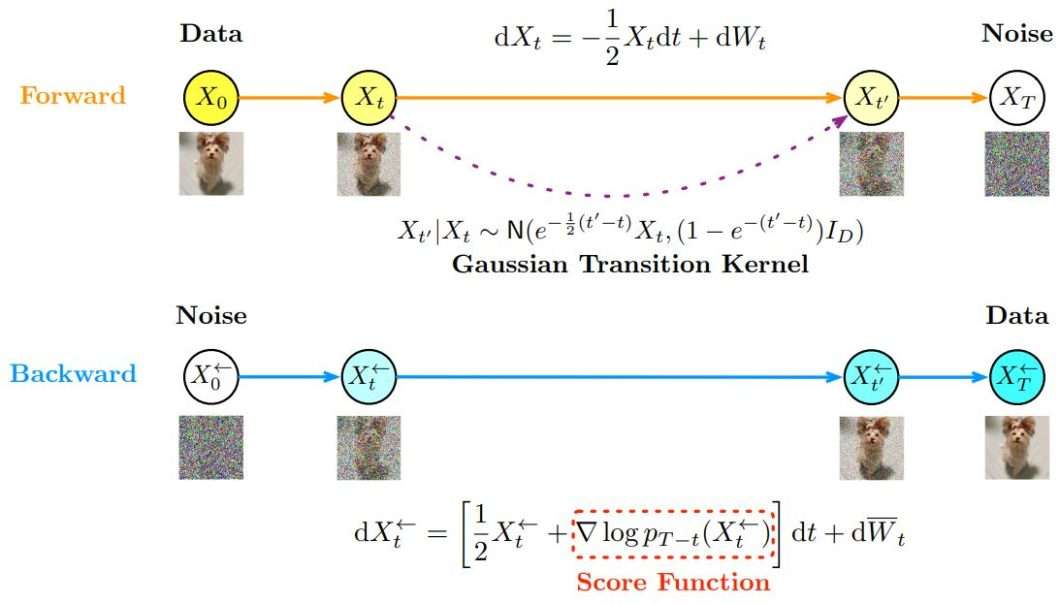
These models use a two-way process of forward noising and backward denoising. During the forward process, Gaussian noise is gradually added to the data until it becomes pure noise. The backward process then involves reversing this noise addition step-by-step, guided by a learned score function. Even though GANs and VAEs reached striking generative results in images and audio, diffusion models reached state-of-the-art performance with novel training techniques, sampling methods, and score functions. They also opened the door for further development and better results in fields like text-to-image generation.

However, diffusion models still suffered with output image quality, not all its generations were great. One of the most notable developments with diffusion models is the addition of transformers, creating Diffusion-Transformer models (DiT). One good example of this is the stable diffusion model. This development uses the simplicity of the diffusion process, with the attention of transformers creating even better results with less computational cost compared to transformers.
Next, let’s take a look at how we can use those generative AI models in real-world use cases.
Applications and Usage of Generative AI
Ever since the introduction of generative AI in its simplest forms, our imagination has been limitless for its potential. However, with recent enhancements, generative AI is no longer just in our imagination. Its applications rapidly transform industries and revolutionize how we create and interact with digital content.
These models are being leveraged to solve real-world problems in diverse fields, offering efficient solutions and improving outcomes. Let’s explore some of the most promising use cases that demonstrate the versatility and potential of these models.
Content Creation
Generative AI models have become powerful tools for content creators. The kind of transformation these models and tools have brought into the creative landscape has been quite useful and may even be controversial. Art, design, music, videos, and writing, have all been influenced by generative AI.
- LLMs: Models like GPT-3.5 and beyond are widely used for content creation. Some fine-tuned variations are good at drafting articles and blog posts or generating creative pieces like poems and short stories. Because of the transformers-based architectures, these models are good at understanding the context and producing coherent text, but they are not a replacement for writers. We already have ways to detect AI-generated content. However, LLMs do offer great help with brainstorming, outlining, and helping writer’s block, enhancing the creative process rather than replacing it.

A poem generated by the early GPT-3 model – Source

- Image generation: A game-changer for visual content, models like DALL-E, Stable Diffusion, and Midjourney have been used to create all sorts of images. From original artwork, eye-catching thumbnails, realistic natural-scenery images that could fool the average eye, or even image editing and enhancement. However, this sparks both excitement and debate about the future of creativity and the role of artists and designers. Like LLMs, those tools can offer great help, empowering new forms of expression and giving artists and designers a powerful tool to work with.
An image generated using text-to-image stable diffusion – Source - Video: As a relatively new field of generative AI, video generation has been giving striking results. Models like Sora by OpenAI have shown us videos that are almost too real to be generated, other models have been following that are doing this as well. These models can be useful with a wide range of content creation tasks.

Sales and Marketing
One of the popular use cases of generative AI is in the field of sales and marketing. Generative models can automate the creation of email campaigns, generate targeted social media posts, craft persuasive product descriptions, and automate customer interactions. This significantly reduces the time and effort needed for such tasks, ultimately enhancing engagement and driving conversions. Although they don’t replace marketers and salespersons, generative AI tools can help free their time to focus on actual leads as well as strategy and creativity.
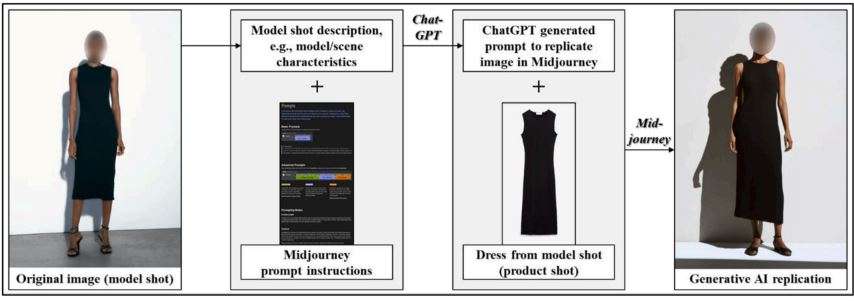
For example, fashion brands have been using generative AI methods to replicate model shots, creating high-quality social media posts with many poses for the same dress and model. In every other industry, generative models like LLMs are being used for chat-bots, driving conversion, and ultimately more sales. Chatbots are getting so much better that they are now hard to recognize from a real representative.
Even when it comes to other businesses, generative AI can make compelling product descriptions, or generate pro-shots for your product. Furthermore, generative models can be used to generate personalized recommendations based on customer data analysis which improves targeting. However, we have to keep in mind the ethical considerations when using generative AI in such use cases as data privacy or misleading content can be a real concern.
Others
The potential of generative AI extends to many more fields, offering solutions to challenges and streamlining tasks across industries. Here are just a few examples of how this technology is being applied.
- Healthcare: Generative AI can create realistic synthetic medical data like X-rays, and patient histories, to train healthcare professionals on a wider range of cases. Additionally, with the help of AR technology, it can generate 3D models of anatomical structures for immersive learning experiences, aiding in surgical training and diagnosis.
- Finance: Streamlining financial operations, generative AI can automate the creation of documents like invoices, contracts, and reports, saving time and reducing errors. It can also generate personalized financial reports for clients based on their data.
- Education: Generative AI can personalize learning materials, create interactive quizzes, and even generate summaries of complex texts. This can improve student engagement and cater to diverse learning styles.
The Future Of Generative AI
Generative AI has the potential to transform our lives in numerous ways, from boosting creativity and productivity to solving complex problems in diverse fields. We’ve only started to scratch the surface of what’s possible, and the future looks bright for this technology.
However, as generative AI becomes more sophisticated and integrated into our lives, it’s crucial to address the ethical considerations that arise. Can we trust AI-generated content? How do we ensure that these models don’t have harmful biases? What about intellectual property and the role of human creativity? These are just a few questions that need careful consideration as we move forward.
Generative AI is a powerful tool, but it is up to us to use it responsibly and ethically. By understanding its capabilities, limitations, and potential impact, we can harness its power for good and create a future where AI truly enhances human creativity and innovation.
To learn more about AI Models, we suggest reading our other blogs:
- What are Graph Neural Networks (GNNs)?
- Introduction to DETR: End-to-End Object Detection With Transformers
- Edge Intelligence: Edge Computing and ML Explained
- Everything You Need to Know about Artificial Neural Network
- Guide to DeepLab Visual Processing Methods
